In-Depth
Understanding Retrieval-Augmented Generation (RAG) and Vector Databases for Not-Quite Dummies
- By Pure AI Editors
- 03/03/2025
Retrieval-augmented generation (RAG) and vector databases are essential parts of all modern AI systems that use natural language. You should understand RAG and its underlying technology, vector databases, in order to make good business decisions related to buying and implementing AI systems.
Luckily, the ideas are simple and easy to grasp. In a nutshell, RAG adds custom content to a natural language system so that the responses generated by a user prompt are more detailed. The custom content is stored in a special kind of database called a vector database.
Suppose you work for the Acme Company, which creates products and services for the hospital industry. Acme currently uses a generative system based on ChatGPT. And suppose a potential new customer asks your AI system, "Why should I use the Acme blood analysis machine?"
Because your chat system is based on the GPT-x large language model, your system has a good grasp of English grammar, and has a good deal of general knowledge available from online sources such as Wikipedia. Your system can give a general answer related to the advantages of automated blood analysis versus manual analysis. But your system can't give detailed information to potential customers.
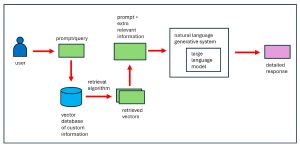 [Click on image for larger view.] Figure 1: Retrieval-Augmented Generation
[Click on image for larger view.] Figure 1: Retrieval-Augmented Generation
The solution is to store all kinds of Acme technical and marketing documents into a vector database. A RAG system accepts a user prompt, sends the prompt to the vector database, gets relevant information from the database, adds the information to the original prompt, and then uses the GPT-x functionality to generate a detailed response. The process is illustrated in Figure 1.
Vector Databases
The key technology that enables RAG is a vector database. Standard SQL databases store highly structured information but are not suitable for storing documents. The RAG process starts with a document of custom information in ordinary text form. The text is broken into chunks, typically anywhere from a single sentence to several pages. A paragraph is a common chunk size.
Now, suppose one sentence in a chunk is, "The Acme Z-100 blood analysis machine has been shown to have a false positive rate of just 0.03 percent." Each word or word fragment is converted to an integer, for example, "The" might be converted to 15 and "Z-100" might be converted to 68 and 1056.
Next, each integer is converted to a vector of roughly 100-500 floating point values such as (0.3456, -0.9876, . . . 1.0123). The idea here is that many words have multiple meanings. For example, the work "bank" can mean a financial institution, an airplane maneuver, the side of a river, and so on. Mapping to a vector of multiple floating-point values handles multiple meanings. All the vectors that represent the source document are stored in a database designed specifically to do this.
To recap, documents are broken down into tokens (a word or word fragment). Tokens are mapped to integers. Integers are mapped to a vector of floating-point values, called word embeddings. The vectors are stored in a vector database.
Approximate Nearest Neighbor Search
The key to making RAG work is quickly retrieving relevant information from the vector database. The most common approach is to use a technique called approximate nearest neighbor search. If you have a prompt, it's not feasible to search the entire vector database from beginning to end looking for entries that are similar to the prompt.
All RAG systems use one of several different algorithms to find a very close vector to the input prompt vector. These algorithms all preprocess the vector database in some way. One simple technique is to cluster the entries in the database so that similar vectors are in the same cluster and each cluster has a single representative vector. When a new prompt is submitted, the system scans only the representative vectors, finds the most similar, and then closely examines only vectors belonging to the associated cluster.
There are several vector database search algorithms that are more sophisticated than ordinary clustering. Three common techniques are hierarchical navigable small world (HNSW), approximate nearest neighbors oh yeah (ANNOY), and locality-sensitive hashing (LSH).
What's the Point?
AI systems are now so complex that it's unlikely you and your company will ever implement one from scratch. This means you'll be buying services from a major technology provider such as Microsoft, Amazon, Meta, and Google, or from one of dozens (at least) nimble startup companies. You won't be buying a standalone retrieval-augmented generation system or its underlying vector database and retrieval algorithm -- they will be part of a much, much larger system you are buying.
All the companies who are trying to sell you an AI system will want to highlight the differentiating characteristics of their particular system. You might be subjected to sales information that touts the technical advantages of a specific vector database architecture or a retrieval algorithm. But far more important are factors related to how well you can integrate an AI system into your existing business systems, and how well you can adapt an AI system to meet your specific needs.
Because AI systems are so large and complex, once you buy into a particular system, it's likely you will be locked in with one company. Therefore, you should analyze carefully to see if the company you buy a RAG system from also has AI services you might need in the future. Choosing the wrong RAG provider can have serious consequences.
Dr. James McCaffrey, from Microsoft Research, works with the technologies that power RAG and vector databases. We asked him to comment. "The pace at which AI systems are evolving is truly astonishing," he said. "But it's important for business decision makers to not get lost in a sea of detailed technical information, such as which retrieval algorithm a RAG system uses. For most companies, the important issues in AI systems are the same as always: return on investment and customer satisfaction."
McCaffrey added, "The technical details of a proposed AI system are critical. It's important that a company's technical experts be included in the decision-making process, in order to avoid buying into an AI system that's incompatible with the company's existing infrastructure. Sadly, in my experience, bad-decision scenarios like this are more common than you might guess."