In-Depth
Understanding AI Language Translation
- By Pure AI Editors
- 08/01/2024
Several kinds of AI problems are related to natural language. Some of the common problem types include question answering, text summarization and language translation. There are many explanations of language translation available online, but they tend to be too technical or too vague.
Ordinary language translation, such as English-to-Italian, has become a commonplace technological commodity. Well-known systems are Google Translate, Microsoft Translator and Amazon Translate. But there are scenarios where a company might want to implement a custom language translation system. Example scenarios include a very high volume of translation text, domain-specific input text and confidential input text.
The Pure AI editors asked Dr. James McCaffrey from Microsoft Research to put together a concrete example of language translation, with an explanation intended for people who are not computer programmers, and with an emphasis on the business implications for an organization that wants to implement a custom language translation system.
Two Different Approaches for Language Translation
One approach for performing language translation is to use an AI service such as Microsoft Azure, Google Cloud Services, or Amazon AWS. This is a high-level approach and has the advantage of being relatively easy to use.
The five main disadvantages of using an AI service are:
- Doing so locks you into the service company's ecosystem to a great extent
- It's difficult to customize the translation service for specialized scenarios
- Security can be an issue if sensitive information is being translated
- AI services are mostly black-box systems where it's often difficult or impossible to know what the system is doing
- A translation service can be pricey if large numbers of documents must be translated
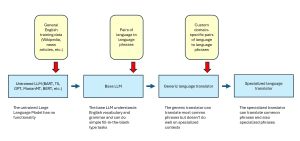 [Click on image for larger view.] Figure 1: AI Language Translation Systems
[Click on image for larger view.] Figure 1: AI Language Translation Systems
A second approach for doing language translation is to implement an in-house system to do so. This approach gives maximum flexibility but requires in-house machine learning expertise or the use of a vendor with ML expertise.
The diagram in Figure 1 presents an overview of language translation systems. To implement an in-house language translation system, in almost all cases you'd start with a generic language translator that was created from a base large language model and then fine-tune the translator using your own custom data.
A Demo Program
An example of a custom language translation program is shown in Figure 2. The example uses the "Helsinki-NLP/opus-mt-tc-big-en-it" open source English-to-Italian model as a starting point. That model is based on the open source MarianMT machine translation model, which is hosted on the HuggingFace open source platform.
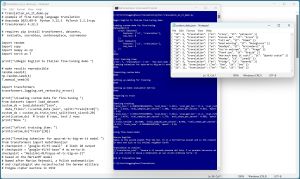 [Click on image for larger view.] Figure 2: Program that Trains an English to Italian Translator
[Click on image for larger view.] Figure 2: Program that Trains an English to Italian Translator
The demo program fine-tunes the Opus model using dummy custom data to produce a custom English-to-Italian translator. The custom model is fed English input of "Venus is the second planet from the Sun. It is a terrestrial planet and is the closest in mass and size to its orbital neighbor Earth." The translated output is "Venere e il secondo pianeta del Sole. E un pianeta terrestre ed e il piu vicino in massa e dimensioni al suo vicino orbitale Terra."
The custom dummy fine-tuning data is:
{ "id": 0, "translation": {"en": "crazy", "it": "pazzesco" }}
{ "id": 1, "translation": {"en": "Excuse me", "it": "Scusa" }}
{ "id": 2, "translation": {"en": "Tell me", "it": "Dimmi" }}
{ "id": 3, "translation": {"en": "Good morning", "it": "Buongiorno" }}
{ "id": 4, "translation": {"en": "Goodbye", "it": "Arrivederci" }}
{ "id": 5, "translation": {"en": "You're welcome", "it": "Prego" }}
{ "id": 6, "translation": {"en": "Thank you", "it": "Grazie" }}
{ "id": 7, "translation": {"en": "How much does it cost?", "it": "Quanto costa?" }}
{ "id": 8, "translation": {"en": "Monday", "it": "Lunedi" }}
{ "id": 9, "translation": {"en": "Friday", "it": "Venerdi" }}
{ "id": 10, "translation": {"en": "One", "it": "Uno" }}
{ "id": 11, "translation": {"en": "Two", "it": "Due" }}
In most situations, many thousands of custom data items are needed to implement a language translator. The demo data is not special and is just used for simplicity. The demo data is in JSON format which is the most common format for custom training data.
The three major expenses when developing most custom AI systems are:
- Creating the data
- Implementing the AI system (usually using the Python language with the PyTorch library)
- Integrating the AI system into existing company systems
All three components can be very expensive so a careful cost-benefit analysis is an absolute must before diving in headfirst.
The first part of the demo output is:
Begin English to Italian fine-tuning demo
Loading custom data for fine-tuning
Generating train split: 12 examples [00:00, 437.04 examples/s]
DatasetDict({
train: Dataset({
features: ['id', 'translation'],
num_rows: 8
})
test: Dataset({
features: ['id', 'translation'],
num_rows: 2
})
})
Done
The demo program reads in the 12 dummy items and extracts 10 of them. When developing an AI system, small datasets must be used until all the bugs are worked out of the system. The 10 data items are split into an 8-item set for training and a 2-item set for testing.
The DatasetDict shows how the data is stored internally. The point is that developing an AI system requires specialized programming knowledge. The implication is that it's not feasible to toss a request to "implement an AI system" to a company's IT department.
Training the Custom Language Translator
The next part of the demo program output is:
Creating tokenizer for opus-mt-tc-big-en-it model
Done
Tokenizing custom data
Map: 100%|***************| 8/8 [00:00<00:00, 206.48 examples/s]
Map: 100%|***************| 2/2 [00:00<00:00, 82.27 examples/s]
Done
Setting up padding for training
Done
Setting up model evaluation metrics
Done
Preparing to train
Done
Tokenization is a key part of any AI natural language processing system. A tokenizer breaks input (typically a sentence or two) into tokens which are usually words, or in some cases, word fragments. Every large language model has an associated tokenizer and in general these tokenizers are not compatible with each other.
The next part of the output shows training progress:
Starting training
{'eval_loss': 4.2402567863464355, 'eval_bleu': 5.3411, 'eval_gen_len': 11.5,
'eval_runtime': 1.4639, 'eval_samples_per_second': 1.366,
'eval_steps_per_second': 0.683, 'epoch': 1.0}
{'eval_loss': 3.6332175731658936, 'eval_bleu': 5.3411, 'eval_gen_len': 11.5,
'eval_runtime': 1.4211, 'eval_samples_per_second': 1.407,
'eval_steps_per_second': 0.704, 'epoch': 2.0}
{'train_runtime': 18.892, 'train_samples_per_second': 0.847,
'train_steps_per_second': 0.212, 'train_loss': 4.5691661834, 'epoch': 2.0}
Done
The demo trains for just two iterations. In a non-demo scenario, with a large set of training data, training can take many hours or even days of processing time. The output shows an "eval_bleu" metric. BLEU (bilingual evaluation understudy) is standard way to evaluate the quality of text which has been machine-translated from one natural language to another.
Using the Custom Translator
The demo program uses the fine-tuned model. The output is:
Source English:
Venus is the second planet from the Sun. It is a terrestrial planet and
is the closest in mass and size to its orbital neighbor Earth.
Translation to Italian:
[{'translation_text': 'Venere e il secondo pianeta del Sole. E un
pianeta terrestre ed e il piu vicino in massa e dimensioni al suo
vicino orbitale Terra.'}]
In a non-demo scenario, the trained model would be saved to a company server or perhaps a cloud service. The Python code that generated the output is surprisingly simple. But as mentioned above, integrating the custom translator into existing IT infrastructure is a major challenge.
So, What's the Bottom Line?
Dr. McCaffrey commented, "Implementing a custom AI solution is very difficult, time-consuming, and expensive. In most situations, organizations just don't have the in-house expertise to tackle these systems. Furthermore, there are very few vendors who have such AI development expertise. Most of the clients I have dealt with have decided that using a service from a large provider like Amazon, Google or Microsoft, is a better option."
He added, "That said, there are scenarios where implementing a custom AI service, such as a domain-specific language translator, is necessary. The demo program explained in this article shows that such systems can be created."