How-To
Researchers Explore Deep Neural Memory for Natural Language Tasks
- By Pure AI Editors
- 02/10/2020
Researchers at Microsoft have demonstrated a new type of computer memory that outperformed many existing systems when applied to a well-known benchmark set of natural language processing (NLP) problems. The memory architecture is called metalearned neural memory (MNM), or more generally, deep neural memory.
The idea was presented at the 2019 NeurIPS conference in a research paper titled "Metalearned Neural Memory" by authors T. Munkhdalai, A. Sordoni, T. Wang, and A. Trischler. A draft version of the paper was available at https://www.microsoft.com/en-us/research/uploads/prod/2019/07/MNM_camera_ready.pdf at the time this post was written.
The PureAI editors got a chance to speak to several members of Microsoft Research and asked them to describe deep neural memory.
At the hardware level, a computer's memory cell can be directly accessed by its address. For example an assembly language instruction like MOV AX, [EX] might mean something like, "put a copy of the value at the memory address that is stored in register EX into register AX." At a higher level of abstraction, a programming language statement like x := mydata[0] could mean, "store a copy of the value in the first cell of array mydata into variable x." In both examples a value of some sort is retrieved by a key of some sort. The memory mechanism is static, there is no relationship between adjacent or nearby memory values, and there is no generalization.
Neural memory is significantly more sophisticated than standard read-write memory. The fundamental idea of neural memory is not entirely new. In the most basic sense, a neural network is a complex math function that accepts one or more numeric input values (inputs such as words in a sentence must be converted to numeric vectors) and returns one or more numeric output values. The idea of neural memory is to store data inside a neural system. The input acts as a key and the memory value is the output returned by the neural system. Such memory can, in principle, have relationships and generalize.
Tsendsuren Munkhdalai, based in Montreal, is the lead author of the research paper. He commented, "One of the main motivations for the proposed memory system was associative memory mechanism and its plasticity based implementation, i.e. Hebbian learning."
He added, "I found it exciting that one can learn a global memory based on a local layer-wise update via meta-training."
We talked to Redmond-based Microsoft research engineers Ricky Loynd and James McCaffrey about the deep neural memory idea. McCaffrey commented, "The MNM neural memory is a fascinating idea that's especially intriguing because it appears that it may be more biologically plausible than simple computer read-write memory."
Loynd added, "Unlike simple memory, neural memory can generalize. With standard read-write memory, if you attempt to access the memory using a key that doesn't correspond to a stored value, you will get an error. But with neural memory the system can generalize and retrieve a meaningful value."
The Microsoft research team used a novel architecture that combines a feedforward network to store memory values and a recurrent neural network to act as a controller for reading and writing values. A simplified schematic for a deep neural memory write operation is shown in Figure 1.
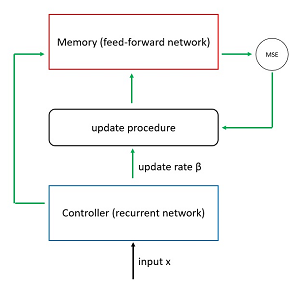 [Click on image for larger view.] Figure 1: Metalearned neural memory write operation. The control flows for a read operation are not shown.
[Click on image for larger view.] Figure 1: Metalearned neural memory write operation. The control flows for a read operation are not shown.
One of the major challenges of working with neural memory is performance. To improve performance, the Microsoft team used an innovative training algorithm that doesn't require Calculus gradients.
The research paper noted that in order to write to a neural network memory rapidly, in one shot, and incrementally, such that newly stored information does not distort/corrupt existing information, the research team adopted training and algorithmic techniques from the field of metalearning.
The research team tackled the bAbI (pronounced "baby") benchmark dataset. The dataset is a collection of 20 sets of tasks intended for use by researchers who work with natural language processing, in particular "QA" tasks (which means question-and-answer, not quality assurance). The motivation for the dataset is that if researchers use a common set of tasks like bAbI, they’ll be able to compare results more easily. Note: We contacted the creators of the bAbI dataset and they told us that bAbI is not an acronym, but they intentionally embedded "AI" in the name.
Here is an example of one-supporting-fact bAbI QA tasks:
1 Mary moved to the bathroom.
2 John went to the hallway.
3 Where is Mary? bathroom 1
4 Daniel went back to the hallway.
5 Sandra moved to the garden.
6 Where is Daniel? hallway 4
7 John moved to the office.
8 Sandra journeyed to the bathroom.
9 Where is Daniel? hallway 4
10 Mary moved to the hallway.
11 Daniel travelled to the office.
12 Where is Daniel? office 11
13 John went back to the garden.
14 John moved to the bedroom.
15 Where is Sandra? bathroom 8
As the name bAbI suggests, the tasks are relatively simple -- for a human.
The number after the answer to a particular question is the number of the one statement that’s needed to answer the question. The bAbI tasks are challenging for a computer because the information must be read sequentially and remembered in order to be able to answer each question.
The MNM system showed impressive results on the bAbI tasks. The MNM model solved all of the tasks with near zero error, outperforming the previous best published results. The MNM system was also compared against a standard recurrent LSTM (long, short-term memory) with SALU (soft-attention lookup table) architecture. Multiple LSTM+SALU runs did not solve any bAbI task and converged to 77.5% mean error. Using same number of iterations, the MNM architecture solved 16.5 tasks on average and converged to a 9.5% mean error.
The MNM memory scheme and deep neural memory architectures in general are somewhat speculative and forward looking but appear very promising. McCaffrey noted, "Deep neural memory just feels right. Common NLP model architectures such as LSTM networks essentially store memory as a one-dimensional vector. This approach has clear limitations. But deep neural memory architectures such as MNM appear to have the potential to form the basis of very powerful language models."
In addition to the bAbI tasks, neural systems using MNM neural memory were shown to achieve strong performance on a wide variety of other learning problems, from supervised question answering to reinforcement learning.