In-Depth
Understanding AI Large Language Model Transformers: an Analogy for Mere Mortals
- By Pure AI Editors
- 05/01/2025
The inner workings of large language models (LLMs) such as GPT-x from OpenAI are incredibly complex. The key component of all LLMs is a software module called a Transformer.
Many explanations of Transformers are too detailed for non-engineers, and many explanations aren't detailed enough to provide useful information for business professionals. This Pure AI article is an adaptation of internal training material used by a huge tech company to get its employees started with AI and Transformers.
An Analogy
Imagine that a large language model is a factory for the Acme Company. The goal of the factory is to accept raw materials in the loading dock, process the raw materials, manufacture a useful product, and ship it to customers. The raw materials are analogous to a sequence of words that asks a question such as, "How can I make an apple pie?" The end product is analogous to detailed instructions for making an apple pie.
The factory has different departments such as payroll to pay workers, security to prevent theft, human resources (nobody is quite sure what they do), and accounting to monitor resources. But the most important department is manufacturing where all of the work gets done.
Acme manufacturing department employees are in one of eight job positions: 1.) loading dock, 2.) material sorters, 3.) high level supervisors, 4.) low level supervisors, 5.) analysts, 6.) expediters, 7.) ordinary assemblers, and 8.) final assemblers. The manufacturing department is analogous to an LLM Transformer module.
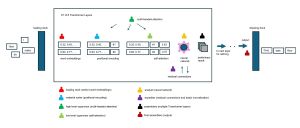 [Click on image for larger view.] Figure 1: The Acme Company Manufacturing/Transformer Department
[Click on image for larger view.] Figure 1: The Acme Company Manufacturing/Transformer Department
- Loading Dock Input (Word Embedding)
The Acme factory loading dock receives a raw materials message that isn't ready for use. The loading dock employees process each word in the input text message into a set of numbers (a vector) in a process called word embedding.
- Material Sorters (Positional Encoding)
The order in which the materials (words expressed now as vectors) is received is important. The sequencer employees tag each input word-vector with a sequence number in a process called positional encoding. This is a relatively simple process.
- High Level Supervisors (Multi-Headed Attention)
The high-level supervisors oversee the flow of information through the factory, looking at both the input streams and the output streams in a process called multi-headed attention. The multi-headed attention mechanism assigns a numeric value to each part of the streams that can be used to determine their relationship to each other. Because this process is important, the supervising is duplicated ("multi-headed") and results
- Low Level Supervisors (Self-Attention)
A second set of supervisors looks carefully at individual input streams in a process called self-attention. Self-attention assigns a numeric value to each word embedding in a particular steam that determines the relationships between each word. For example, "If I wanted to bake a cherry pie, how would I do it?" will assign a higher relationship between "it" and "bake" than to "it" and "cherry".
- Analysts (Neural Networks)
The analysts do most of the difficult behind-the-scenes work. They collect all the information from the material sorters/taggers and supervisors and perform complex calculations using a neural network. The neural network combines the previously processed information and generates a preliminary (not yet final) product set of instructions in numeric form.
- Expediters (Residual Connections)
The expediters continuously monitor the outputs produced by the analysts and check them against the original numeric inputs in a process called residual connections. The expediters also perform quality control to guarantee consistency in a process called layer normalization.
- Ordinary Assemblers (Multiple Transformer Layers)
At this point all the complex information is sent to the assemblers who combine everything to produce an output. The output is then sent to another team of assemblers who repeat the process to refine the output, which is then sent to another set of assemblers, and so on. Each set of assemblers is analogous to a Transformer layer. The number of assembler teams varies but six is the normal default.
- Final Assemblers (Output)
The final assemblers take the numeric output produced by the teams of ordinary assemblers and convert it to a final output stream in text form that consumers can understand, and then emit the final output. This is a relatively simple process.
Wrapping Up
The Pure AI editors asked Dr. James McCaffrey from Microsoft Research for comments. He noted, "Any explanation of a complex topic using an analogy will have slight inconsistencies and inaccuracies. For large language models, diving directly into the topic at a detailed level is an exercise in futility and frustration for beginners. Transformers and LLMs are just too complicated."
McCaffrey added, "But understanding Transformers has to start somewhere. An analogy like the one presented in this article has proven very useful for many people with many different backgrounds."