How-To
How To Create an AI Assistant
- By Pure AI Editors
- 08/02/2023
The ChatGPT chatbot is an AI application that was built by fine-tuning the GPT-3 large language model. ChatGPT is a general-purpose, question-and-answer assistant application and can be used as-is for things like lightweight report generation (somewhat to the concern of school teachers everywhere). One of the hottest areas of AI research and practice is fine-tuning large language models (LLMs) to create domain specific AI assistants. Examples include financial planning assistants, sports betting assistants, preliminary medical diagnosis assistants and so on.
 [Click on image for larger view.] Figure 1: Images of AI Assistants Created by the DALL-E Image Creation Assistant
[Click on image for larger view.] Figure 1: Images of AI Assistants Created by the DALL-E Image Creation Assistant
Just what is involved in creating an AI assistant? The Pure AI editors asked our technical experts to explain AI assistants and the process of creating them in terms that an ordinary human can understand. In order to make the explanation understandable, our experts have used simplified terminology and omitted low-level details that obscure the main ideas.
The Foundations
An AI assistant starts with an LLM. The two most well-known LLMs are BERT and GPT-3, but there are many new LLMs being created by research organizations and corporate entities. BERT (Bidirectional Encoder Representations from Transformers) was created by Google in 2018 and is an open source effort. GPT-3 (Generative Pre-trained Transformer) was created by OpenAI in 2020 and was originally intended to be open source but is now a proprietary, pay-for-use system.
An LLM can be loosely thought of as a fantastically complex mathematical equation that predicts the next word in a sentence. As an analogy, imagine that you want to predict the probabilities for each of three poker players, A, B, C, to indicate which of them will win a poker tournament. Hypothetically, you could construct a prediction equation like P = 0.13 + (1.23 * x1) + (-0.99 * x2) + (0.84 * x3) where x1, x2, and x3 are inputs such as years of experience of player A, current tournament winnings by player B and so on.
The four numbers -- 0.13, 1.23, -0.99, 0.84 -- are called the model weights and they are determined by looking at thousands of previous poker tournament results. This is called training the model. A model with four weights is said to have four trainable parameters. The terms model weights and trainable parameters are synonymous. The output of the trained poker player model would look like P = (0.25, 0.40, 0.35) indicating that player B has the largest probability of winning at p = 0.40.
Large Language Models
An LLM accepts a sequence of word inputs that have been converted into numbers, for example, "the" = 5, "bird" = 209, "laid" = 6317, "an" = 8. The output of the LLM would be a set of roughly 200,000 probabilities that represent the likelihood of each possible word in the English language. You would expect the probability of "egg" to be high, perhaps 0.95, and the probability of "car" to be quite small, nearly zero.
Large language models are just that -- large. The BERT LLM has 340 million trainable parameters. The GPT-3 LLM has 175 billion trainable parameters. Because an LLM has a lot of weights/parameters, they are organized into software layers. Training an LLM is accomplished by feeding the model a huge amount of text information, typically the entire text of Wikipedia plus books, newsfeeds and other sources. Training an LLM from scratch requires enormous processing power using fast GPU chips and huge amounts of computer memory, potentially costing millions of dollars.
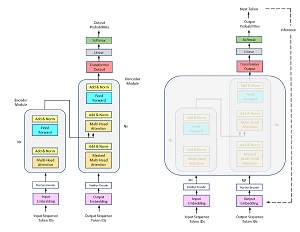 [Click on image for larger view.] Figure 2: Large Language Models are Based on Transformer Architecture
[Click on image for larger view.] Figure 2: Large Language Models are Based on Transformer Architecture
From an engineering perspective, the key component of an LLM system is a complex software module called a Transformer. A Transformer is a highly specialized form of a neural network. Transformer architecture was introduced in 2016 and is an evolution of an earlier architecture called LSTM (long, short-term memory).
A trained LLM is essentially an English language expert but one who has limited knowledge of anything beyond language rules and syntax. By adding specific knowledge, such as the text of a set of financial planning reports, the LLM can be turned into an AI assistant. This is called fine-tuning the LLM. So, another way of thinking about an LLM is that it is like a 12-year-old child who has mastered English and is now ready to go to seventh grade to learn topics such as algebra and history.
Four Ways to Fine-Tuning a Large Language Model
There are many ways to fine-tune an LLM and there is intense research activity in this area. There are significant new results published every few weeks. In addition to academic efforts, it is highly likely that there are secretive efforts being made by governments who see AI systems as critical to national security.
The most obvious approach for creating an AI assistant is to start with a blank LLM (all trainable parameter values effectively set to zero) and train it using standard text corpuses like Wikipedia and also problem-specific text such as financial reports. As a general rule of thumb, this approach works very well but is by far the most expensive and time-consuming. The train-from-scratch approach is rarely feasible in practice, except by very large corporations and governments.
A second approach for creating an AI assistant is to start with a trained LLM, typically BERT, and supply additional training with problem-specific text. This approach modifies the existing internal LLM weights and so the trained assistant essentially loses some of its basic language knowledge. A variation of this technique is to freeze the weights in most of the LLM layers so that they don't change, but allow the weights in a few of the layers to be changed by the additional training. This approach is much easier than training from scratch but still requires significant effort.
A third approach for creating an AI assistant is to add new trainable parameters into the base LLM by modifying the LLM architecture. Because LLM architecture is so complex (see Figure 2), there are dozens of ways to modify the model internally. This approach is sometimes called adding adapters. An analogy is modifying an automobile engine by boring out the cylinders or changing the camshaft. Modifying LLM internal architecture is effective but requires a lot of deep engineering expertise. An interesting new category of software services creates LLM models with built-in adapters that are relatively easy to fine-tune.
A fourth approach for fine-tuning an LLM in order to create an AI assistant is to add completely new layers of weights, augmenting the existing LLM. A loose analogy is adding a turbocharger to an automobile engine. This approach has the benefit of not disturbing the base LLM weights and is also the easiest -- relatively. All of the techniques for fine-tuning an LLM are difficult and require significant effort.
Wrapping Up
One of the Pure AI technical advisors is Dr. James McCaffrey from Microsoft Research, who noted that research related to fine-tuning LLMs to create AI assistants is the subject of intense academic and corporate efforts. Keeping up with new developments, he said, is a big challenge.
"Existing techniques all require deep technical expertise, and given the supply-demand in AI, these current techniques are not feasible for most small companies," McCaffrey said. "Companies face a classic problem -- create an AI assistant sooner and try to get an early competitive advantage, but at high expense, or create one later at lower expense but at the risk of losing ground to competitors."
McCaffrey further speculated, "There are many efforts in the AI space to create systems that can more or less automatically create AI assistants. Because there is so much money at stake, I expect such systems to be developed rapidly over the next few months by AI startup companies.
"AI assistants are related to the ideas of general artificial intelligence (GAI) and super artificial intelligence (SAI). One school of thought is that GAI can be achieved by constructing hundreds or thousands of specialized AI assistants. Another thought is that GAI can be achieved by one enormous AI system that has been fine-tuned on hundreds of specific problem domains."