How-To
Researchers Create a Computer Program that has Superhuman Skill at Stratego
Stratego is extraordinarily difficult for computers because the game has imperfect information (opponent pieces are hidden, which allows bluffing) and sheer size -- the number of possible positions vastly exceeds the number of atoms in the known universe.
- By Pure AI Editors
- 05/05/2023
Researchers at Google have demonstrated a new algorithm that achieves superhuman performance on the Stratego board game. The technique is explained in the 2022 research paper "Mastering the Game of Stratego with Model-Free Multiagent Reinforcement Learning" by J. Perolat et al.
Researchers have explored applying artificial intelligence to game playing for decades, starting with chess in the 1950s. Chess was essentially conquered when the Deep Blue program beat world champion Garry Kasparov in 1997. Other games that have been successfully tackled to a large extent include poker, Go, video games and Diplomacy.
The strategy board game known as Stratego (the name is copyrighted, but there are many versions of the same game with different names) is deceptively simple and can be played by children. However, Stratego is extraordinarily difficult for computers. The two key challenges for a software program are that the game has imperfect information (opponent pieces are hidden, which allows bluffing) and sheer size -- the number of possible positions vastly exceeds the number of atoms in the known universe.
Why Stratego is Difficult
In order to understand the new approach to playing Stratego, it's necessary to have a basic understanding of the rules of the game. The image in Figure 1 shows an example starting position. The game is played on a 10x10 board. There are two 2x2 blocks at the center of the board where pieces cannot move. Each player, Red and Blue, has 40 pieces, one of which is the Flag. The goal of the game is to capture the opponent's Flag.
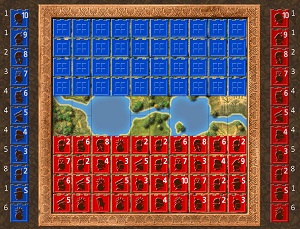 [Click on image for larger view.] Figure 1: Example of an Initial Position
[Click on image for larger view.] Figure 1: Example of an Initial Position
Initially, all pieces are hidden from the opponent. Each player can arrange the 40 pieces in any way. There are six Bomb pieces that do not move and kill any piece that lands on them except a Miner. The other pieces have a point value ranging from 1 (Spy) to 10 (Marshal). The pieces and their point values are shown in Figure 2.
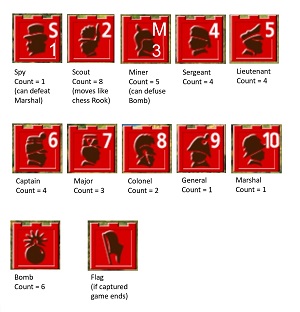 [Click on image for larger view.] Figure 2: Stratego Pieces
[Click on image for larger view.] Figure 2: Stratego Pieces
The regular pieces move one square at a time to an adjacent square (not diagonally). When a piece lands on an opponent's piece, the piece with the lower point value loses and is removed. If both pieces have the same value, both are removed.
The special Scout piece, with value = 2, can move multiple squares in a straight line like a chess Rook. It usually sacrifices itself to identify the type of an opponent's piece.
The Spy piece, with value = 1, can land on and ambush the Marshal that has value = 10. But if the Marshal or any other piece lands on the Spy, the Spy loses.
The Flag piece is almost always placed on the first row where it's less vulnerable, and the Flag is usually surrounded by two or three of the Bomb pieces for protection.
Games between experienced human players typically last about 300 moves and take anywhere from about 20 minutes to two hours. The image in Figure 3 shows a typical game in progress from the point of view of the Red player. Three of the Blue pieces have been exposed by defeating a Red piece. The key to success in Stratego is information extraction -- determining the types of the opponent's pieces.
The Stratego Program
The new Stratego computer program is called DeepNash. The name is a reference to deep reinforcement learning and mathematician John Nash (1928-2015). The research abstract states that DeepNash uses a game-theoretic, model-free deep reinforcement learning method called the Regularized Nash Dynamics (R-NaD) algorithm.
As of 2022, the DeepNash program beats existing state-of-the-art AI methods in Stratego and achieved an all-time top-three rank on the Gravon games platform, scoring a win rate of 84 percent against human expert players.
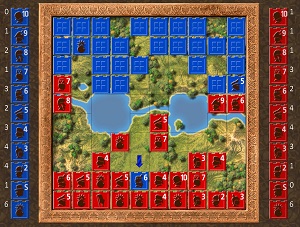 [Click on image for larger view.] Figure 3: Stratego Game in Progress
[Click on image for larger view.] Figure 3: Stratego Game in Progress
To become difficult to exploit, DeepNash develops unpredictable strategies. This includes using initial piece placements that vary enough to prevent its opponent from spotting patterns over a series of games.
The DeepNash program learned a variety of bluffing tactics. For example, the only piece that can defeat a Marshal (10) is the lowly Spy (1). The Spy can be placed in a central location and wait. Then a moderate-strength piece can chase a high-value exposed opponent piece such as a Colonel (8), bluffing that the chasing piece is a General (9). The opponent will use his Marshal (10) to chase the piece thought to be a General and be lured to pass the Spy waiting in ambush.
What Does It Mean?
The Pure AI editors spoke with Dr. James McCaffrey from Microsoft Research, who has experience with AI approaches to games, and experience with deep reinforcement learning, the basis of DeepNash. McCaffrey commented, "The DeepNash program is impressive and represents a significant step forward on the path to mastering complex strategy games with imperfect information."
McCaffrey added, "The key question however, is the extent to which the ideas used programs like DeepNash can generalize. Can the fundamental ideas be applied to useful applications, or are such systems strictly one-off applications that don't readily generalize?"
McCaffrey concluded, "Either way, the Stratego program is an interesting new development in deep reinforcement learning."