News
DARPA Funds the Adversarial Robustness Toolbox (ART) Library for ML Security
- By Pure AI Editors
- 07/05/2022
The Adversarial Robustness Toolbox (ART) library is an open source collection of functions for machine learning (ML) security. The ART library was originally funded by a grant from the U.S. Defense Advanced Research Projects Agency (DARPA) under Contract No. HR001120C0013. Version 1.0 of the ART library was released in November 2019. The library has been under continuous development. See the project's GitHub repo for more information.
The ART library supports most popular ML frameworks including TensorFlow, Keras, PyTorch, MXNet, scikit-learn, XGBoost and LightGBM. The ART library contains a wide range of attack modules (such as the fast gradient sign method evasion attack) and defense modules (such as the fast generalized subset scan detector).
The Pure AI editors spoke to Dr. James McCaffrey, who works at Microsoft Research in Redmond, Wash., about the project. He is an expert in ML and has worked on several advanced ML security projects. McCaffrey noted, "It's possible to implement ML attack and defense modules from scratch, but doing so requires expert-level programming skill and so the process is expensive and time-consuming. The ART library significantly reduces the effort required to explore ML security techniques."
The Four Attack Types
An important step when examining ML model security is to understand how ML models can be attacked. The four main categories of ML attacks are poisoning, inference, extraction and evasion. The diagram in Figure 1 illustrates the relationship between these attacks.
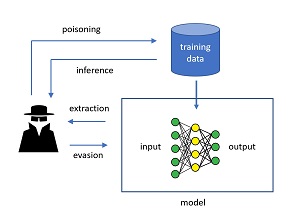 [Click on image for larger view.] Figure 1: Four Categories of Machine Learning Attacks
[Click on image for larger view.] Figure 1: Four Categories of Machine Learning Attacks
Briefly, poisoning attacks insert malicious training data, which will corrupt the associated model. Inference attacks pull information from the training data, such as whether or not particular person's information is in the dataset. Extraction attacks create a replica of a trained model. Evasion attacks feed malicious inputs to a trained model in order to produce an incorrect prediction.
Each of the four ML attack types can be a white-box attack or a black-box attack. In a white-box attack, an adversary has full knowledge of the inner workings of the model being attacked. This typically occurs from an insider but can also occur when too much information about a model is published. In a black-box attack, an adversary has no (or very limited) knowledge of the architecture of the model being attacked.
The Fast Gradient Sign Method (FGSM) Attack Using ART
The screenshot in Figure 2 shows an example of the ART library being used to attack an ML model using the fast gradient sign method (FGSM), one of the best-known white-box evasion attacks. The model being attacked is a classifier for the standard MNIST (Modified National Institute of Standards and Technology) data. Each MNIST data item is a crude 28 by 28 pixel grayscale image of a handwritten digit from "0" to "9."
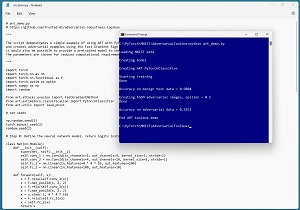 [Click on image for larger view.] Figure 2: Example of the ART Library in Action
[Click on image for larger view.] Figure 2: Example of the ART Library in Action
In the FSGM attack, an adversary starts with benign data and then uses knowledge of the model to create malicious near-copies of the data that have been designed to produce an incorrect prediction. In the demo run, the trained model scores 98.04 percent accuracy (9,804 correct out of 10,000 images) on the test data. The ART library FSGM module creates 10,000 malicious data items. These malicious data items appear very similar to the source benign data items but the trained model scores only 39.52 percent accuracy on the malicious items.
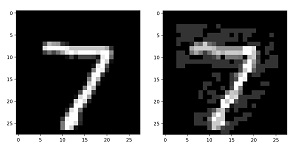 [Click on image for larger view.] Figure 3: A Benign MNIST Item and a Malicious Near-Copy
[Click on image for larger view.] Figure 3: A Benign MNIST Item and a Malicious Near-Copy
The two images in Figure 3 show the first benign test data item, clearly a "7" digit on the left. On the right, next to the benign data item, is the corresponding malicious data item. To the human eye the malicious item is a "7," but the trained model believes the item is a "3" digit.
The FGSM attack is parameterized by an epsilon value between 0.0 and 1.0. The demo program uses epsilon = 0.20. Large values of epsilon trick the trained model under attack more often, but large epsilon values produce malicious data items that are easier to spot by the human eye.
Under the Hood of Fast Gradient Sign Method Using ART
During training, a neural network model is updated using code that looks something like:
compute all weight gradients
for-each weight
new_wt = old_wt - (learnRate * gradient)
end-for
Each neural weight is just a numeric value, typically between about -10.0 and +10.0. The output of the model depends on a particular input and the weight values. During training, each weight has an associated gradient. If a model has 20,000 weights, then there are 20,000 gradients. A gradient is just a numeric value that gives information about how (increase or decrease) to adjust the associated weight so that the model predictions are more accurate. Although it's not obvious, the subtraction operation in the pseudo-code above adjusts the weights so that the model is more accurate (technically, so that the model produces less error). The learnRate parameter is a value, typically about 0.10, that moderates the increase or decrease in the weight value.
For the FSGM attack, malicious data is generated using code that looks something like:
compute all input pixel gradients
for-each input pixel
bad_pixel = input_pixel + (epsilon * sign(gradient))
end-for
For the MNIST dataset, each data item is 28 by 28 pixels, so there are 784 input values per image. In FGSM, only the sign of the input gradient (positive or negative) is used. The addition operation adjusts pixel values so that the model is less accurate. The epsilon value moderates the change between benign pixel value and the malicious value.
Using raw PyTorch code, implementing the FGSM attack looks like:
for (batch_idx, batch) in enumerate(test_ldr):
(X, y) = batch # X = pixels, y = target label
X.requires_grad = True
oupt = net(X)
loss_val = loss_func(oupt, y)
net.zero_grad() # zap all gradients
loss_val.backward() # compute gradients
sgn = X.grad.data.sign()
mutated = X + epsilon * sgn
mutated = T.clamp(mutated, 0.0, 1.0)
Writing code like this requires expert knowledge of PyTorch. Implementing the FGSM attack using the ART library looks like:
art_classifier = PyTorchClassifier(
model=model,
clip_values=(0.0, 1.0),
loss=criterion,
optimizer=optimizer,
input_shape=(1, 28, 28),
nb_classes=10,
)
attack = FastGradientMethod(estimator=art_classifier,
eps=0.2)
x_test_adv = attack.generate(x=x_test)
In order to use the ART library with a PyTorch model, it's necessary to wrap the PyTorch model in an ART library-defined PyTorchClassifier class, but then generating the malicious adversarial attack data is easy.
What Does It Mean?
Dr. McCaffrey commented, "The major challenge facing libraries like the ART library for machine learning security is balancing the tradeoff between the library's learning curve and the benefit from using the library." He continued, "In many cases, the effort required to learn how to use a library isn't worth the benefit gained and so it makes more sense to implement the library functionality from scratch."
McCaffrey added, "In my opinion, the ART library for machine learning security hits a sweet spot in the tradeoff between learning effort and information reward. I have used the ART library to get relatively junior level data scientists and engineers up to speed with machine learning attacks and defenses, and then we later use custom code for advanced security scenarios."