News
Microsoft Advances the State of the Art for Automatic Image Captioning
- By Pure AI Editors
- 10/14/2020
Microsoft researchers have unveiled an artificial intelligence (AI) system called VIVO that can generate captions for images. The accuracy of the captions are often on par with, or even better than, captions written by humans. The VIVO system can accurately provide a caption for an image even when the image has no explicit, direct target captioning in the system training data.
One of the standard benchmark datasets for image captioning is called NOCAPS (Novel Object Captioning Challenge). NOCAPS consists of 166,100 human-generated captions that describe 15,100 images. Many of the classes seen in the NOCAPS training data have no associated training captions, which makes captioning very challenging.
An example of the VIVO (Visual Vocabulary Pretraining) system in action is shown in Figure 1. The old captioning model described the image as, "a man in a blue shirt." The new VIVO-based model generated the superior, "a man in surgical scrubs looking at a tablet".
 Figure 1: The old model generated "a man in a blue shirt," the new model generated "a man in surgical scrubs looking at a tablet." (source: Microsoft).
Figure 1: The old model generated "a man in a blue shirt," the new model generated "a man in surgical scrubs looking at a tablet." (source: Microsoft).
The VIVO system works by separating images and tags during training, and then fine-tuning the results to produce captioning. The VIVO training process is illustrated in Figure 2. First, pre-training uses paired image-tag data, where image region features and tags of the same object are aligned, to learn a rich vocabulary of visual objects. Next, fine-tuning is performed on paired image-sentence data that only need to cover a limited number of visual objects (shown in blue). Finally, the system is designed to be able to describe novel objects (shown in yellow) that were learned during pre-training.
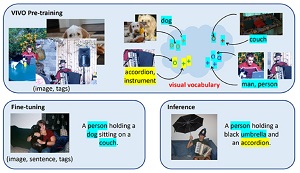 [Click on image for larger view.] Figure 2: The VIVO pre-training separates images and tags during training which allows it to deal with novel objects (yellow).(source: Microsoft).
[Click on image for larger view.] Figure 2: The VIVO pre-training separates images and tags during training which allows it to deal with novel objects (yellow).(source: Microsoft).
The technical details of the VIVO captioning system are described in the paper "VIVO: Surpassing Human Performance in Novel Object Captioning with Visual Vocabulary Pre-Training," by Xiaowei Hu, Xi Yin, Kevin Lin, Lijuan Wang, Lei Zhang, Jianfeng Gao and Zicheng Liu.
Dr. James McCaffrey, from Microsoft Research, commented, "Image captioning is a very difficult problem, and the VIVO system is an impressive technical achievement." He added, "AI/ML image captioning models like VIVO, as well as sophisticated natural language processing models like GPT-3, can have billions of trainable parameters, and therefore require huge compute resources. Enterprises can create custom models for niche problems, using tools such as PyTorch, TensorFlow, or ML.NET, and they can leverage powerful commercial systems like Azure Cognitive Services for scenarios that need massive computing resources."