How-To
Researchers Unveil Working Memory Graph Architecture for Reinforcement Learning
The Pure AI editors keep you abreast of the latest machine learning advancements by explaining a new neural-based architecture for solving reinforcement learning (RL) problems. WMG uses a deep neural technique developed for natural language processing problems called Transformer architecture, and it significantly outperformed baseline RL techniques in experiments on several difficult benchmark problems.
- By Pure AI Editors
- 09/02/2020
Machine learning (ML) researchers have published an interesting new neural-based architecture for solving reinforcement learning (RL) problems. The technique is called Working Memory Graph (WMG) and it was presented at the International Conference on Machine Learning (ICML) in July 2020. WMG uses a deep neural technique developed for natural language processing (NLP) problems called Transformer architecture. In experiments on several difficult RL benchmark problems such as Sokoban, the WMG technique significantly outperformed baseline RL techniques.
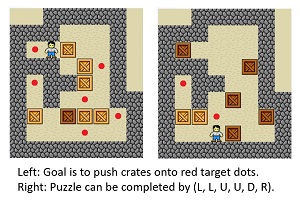 [Click on image for larger view.] Figure 1: Working Memory Graph Architecture Can Solve RL Problems
[Click on image for larger view.] Figure 1: Working Memory Graph Architecture Can Solve RL Problems
Because the WMG technique to solve RL problems is based on the Transformer architecture to solve NLP problems, in order to understand WMG you need to understand Transformer architecture. And to understand Transformer architecture you need to have a basic understanding of gated recurrent neural networks (RNNs), the architecture from which Transformers were derived. Additionally, one of the key mechanisms in both Transformer and WMG architectures is a technique called Attention.
Gated Recurrent Neural Networks
A typical example of an NLP problem is to process a text document of about a page or two, and then produce a one-paragraph summary of the document. Most NLP problems can be thought of as having an input which is a sequence of words. The most common approach for dealing with individual words in an NLP scenario is to convert each word into a vector of numeric values. This is called a word embedding. So, if you have a sentence with five words as input, and each word has an embedding of size four, the raw input to the NLP system would be 5 * 4 = 20 individual numeric values. The size of a word embedding is variable, but for realistic problems the size is often a vector of about 100 numeric values.
One of the earliest breakthrough neural approaches for NLP problems was a gated RNN. In a gated RNN, each word (in embedded vector form) is fed to the RNN, one at a time. As each word in the sentence/sequence is processed, a large internal vector is computed based on the old value of the vector (hence the term "recurrent") and the current input word. In this way the values in the internal vector represent a state, which in theory, holds all the information about the sentence. Computing the state vector uses complicated math "gates." There are many variations of gated RNNs that vary in how their underlying gate computations work. The two most common types of gated RNNs are GRUs (gated recurrent unit) and LSTMs (long, short-term memory).
Gated RNNs are very effective for NLP problems where there are only a few sentences, or with short sentences. For example, an LSTM system can predict the sentiment ("positive," "neutral," "negative") of a short (up to about 10 sentences) movie review with excellent accuracy. However, for very long sentences or documents with many sentences, gated RNNs don't work very well. In practice, it's just not possible to capture all the information about a document or long sentence into a single numeric vector.
Because gated RNN systems read in one word at a time, by the time you reach the 40th word in a long sentence, the information about the first few words is lost within the internal state vector. One way that is used to deal with this problem is to read sentences from beginning to end, and then a second time from end to beginning. These bi-directional gated RNN systems perform better than basic gated RNNs, but still fail on long input sequences.
Attention and Transformer Architecture
The next step in the evolution of neural-based NLP systems was the Attention mechanism. ML Attention is a general technique that can be used in many different architectures. A gated RNN accepts one word at a time (as a word embedding vector of values) as input. Attention architecture adds a value for each pair of words in the sentence, where the value is a measure of how closely related the pair of words are. Words that are closely related have a high Attention value, and words which are not related have a low Attention value.
Consider an input sentence, “The rabbit hopped under a bush because it was scared.” The computed Attention value for (rabbit, it) will be high because the two words refer to the same thing. The Attention value for (bush, it) will be low because the two words refer to different things.
Some architectures make a distinction between attention and self-attention. The difference is that self-attention usually refers to a small scale set of attention values, such as those between nodes in one layer of a neural system, and attention usually refers to larger scale, such as attention values between nodes in different layers.
Adding an Attention mechanism to a gated RNN system for NLP greatly increases the engineering complexity of the system but often results in significant improvements in model accuracy. The Attention mechanism quickly led to a design called Transformer architecture.
Researchers noticed that, surprisingly, if you take a complex gated RNN that has Attention mechanisms, then remove the gated RNN component, the resulting system with just Attention performs as well as, and often even better than, the gated RNN plus Attention system. This idea is often called "attention is all you need," based on the title of the source research paper. Systems that rely only on Attention, without a gated RNN component, are called Transformers. As this article is being written, NLP systems based on Transformer architectures give current state of the art results.
The Working Memory Graph Architecture
Researchers at Microsoft realized that it might be possible to adapt the Attention mechanism and Transformer architecture used for NLP problems to reinforcement learning problems. Consider a Sokoban puzzle like the one shown in Figure 1. The goal is to push each crate onto a red target dot. In the right image, the puzzle can be successfully completed by the input sequence (L, L, U, U, D, R). Solving such puzzles requires a long sequence of moves and planning ahead to avoid configurations such as getting a crate stuck in a corner where it can't be moved. The key idea is that solving a Sokoban puzzle involves finding an input sequence of moves that is similar in some respects to processing a sequence of words in a sentence. Sokoban puzzles are one of the types of RL problems that can be solved using Working Memory Graph architecture.
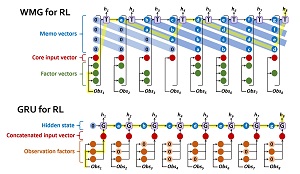 [Click on image for larger view.] Figure 2: WMG vs. Gated RNN for RL Problems
[Click on image for larger view.] Figure 2: WMG vs. Gated RNN for RL Problems
Previous research efforts have applied gated RNNs to RL problems with moderate success. One of the several differences between NLP problems and RL problems is that in NLP, inputs are sequences of words, and words are all similar in some sense. And input words don't explicitly depend on the current state. But in RL problems, the input sequences are actions based on the current state of the system. In RL, state information is sometimes stored into numeric vectors called observation factors.
The two diagrams in Figure 2 show a comparison of a gated RNN solution and a WMG solution for an RL problem. Both diagrams are "unfolded in time," meaning there is just one RNN and one WMG system shown over multiple steps of input. In the WMG system, instead of an observation being represented as a concatenated vector made from several observations factors, an observation is divided into several factor vectors and a single core vector, all of which serve as inputs.
One of the key components of the WMG architecture is a set of "memo vectors." A memo vector holds memory of previous states and Attention is applied to these states. In an NLP problem, there are rarely more than about 30 words in a sentence, and so it's possible to store an Attention value for every possible pair of input words. However, in an RL problem, the number of possible states/observations can be astronomically large (or even infinite) and so it's not feasible to store an attention value for every pair of observations. The memo mechanism stores a subset of recent observations to solve this engineering problem. Notice too, that WMG architecture uses a Transformer module (T in the diagram) rather than a gated RNN (G).
What Does It All Mean?
The technical details of Working Memory Graph architecture are detailed in the research paper "Working Memory Graphs." The paper is available online in PDF format. The Pure AI authors contacted the lead author of the WMG research paper, Ricky Loynd, from Microsoft Research.
Loynd commented, "Reinforcement learning training is too slow for most real-world applications. WMG represents a step towards making RL usable for practical problems, by showing how to structure agent observations and apply Transformers to them in order to obtain much faster learning."
Dr. James McCaffrey, also from Microsoft Research, added, "The WMG architecture appears to be a significant advance in RL theory and practice. WMG is an example of the steadily increasing complexity of ML systems and the merging of ideas from different areas of ML research."
Loynd speculated about where research on WMG might be headed, saying, "I believe the next important step for WMG is to expand the Transformer itself to reason over relations between entities (like words) in the same powerful ways that Transformers already reason over entities themselves."
The WMG research paper was one of over 1,000 research papers and presentations at the 2020 International Conference on Machine Learning. How is it possible to stay current with the incredible pace of development in RL, ML and AI?
Loynd noted, "Every day, I skim the titles of all the papers posted to arXiv that mention RL, and read the handful of abstracts that seem most related to my work. Every day or two, when I see an especially important paper, I’ll read it in more depth and take notes."
McCaffrey added, "To keep up to date, I regularly scan blog posts from industry research organizations, in particular Microsoft Research and Google Research. And increasingly, I rely on news and high-quality summary Web sites such as Pure AI."