How-To
Understanding LSTM Neural Networks – for Mere Mortals
Learn about LSTM (long, short-term memory) neural networks, which have become a standard tool for creating practical prediction systems. Specifically, this article explains what type of problems LSTMs can and cannot solve, describes how LSTMs work, and discusses issues related to implementing an LSTM prediction system in practice.
- By Pure AI Editors
- 11/15/2019
LSTM (long, short-term memory) neural networks have become a standard tool for creating practical prediction systems. In this article I'll explain briefly what type of problems LSTMs can and cannot solve, describe how LSTMs work, and discuss issues related to implementing an LSTM prediction system in practice. The goal is to explain at a level that's not too detailed but not too vague.
What Types of Problems Can an LSTM Solve?
At a high level of abstraction, LSTM networks can be used for natural language processing (NLP). A specific example where LSTMs are highly effective is sentiment analysis – predicting if a sentence or paragraph is negative ("Beyond comprehension"), neutral ("I rate it so-so"), or positive ("Unbelievable service"). Notice that all three mini-examples are somewhat ambiguous.
Why are natural language problems difficult? Consider, "I wish I could say the movie was great but I can't." A naive approach that just examines words would see "movie" and "great" and likely conclude the sentence is a positive sentiment. The words in a sentence form a sequence and the meaning of each word, and the overall meaning of a sentence, usually depend on the ordering of the words.
A standard non-LSTM neural network classifier accepts numeric input values and generates output values that are interpreted as probabilities. For example, suppose you want to predict the political leaning (conservative, moderate, liberal) of a person based on age, gender, years of education and annual income. An input set of (38, 0, 16, 54), meaning a 38-year old male who has 16 years of education and makes $54,000 per year, might produce output values like (0.25, 0.60, 0.15). The conclusion is that the person is a political moderate because that class has the largest probability (0.60).
For problems not related to natural language, standard neural networks often work amazingly well. But the problem with standard neural networks applied to an NLP problem is that they can't take the order of the input values (words) into account.
LSTM networks have an internal memory state that keeps a shadow of each input value in a sequence of inputs. The mechanism is somewhat similar to the way that you can remember the first words of a sentence when someone speaks to you, and use that memory to make sense of the entire sentence.
Word Embeddings for LSTMs
At a very low level, an LSTM sentiment classifier accepts a long sequence of numeric values such as (0.3254, 0.9753, . .) and outputs a small set of numeric values such as (0.25, 0.60, 0.15). If the system is trying to predict (negative, neutral, positive), the conclusion would be neutral because that class has the largest probability.
The numeric input values represent words but not in an obvious way. Each word in an input sentence must be encoded as a vector of values. The number of numeric values per word can vary but typically, in a sentiment analysis problem, each word is encoded as about 100 numeric values. Expressing a word as a vector of numeric values is called a word embedding.
Where do these embedding numeric values for each word come from? There are a handful of freely available embedding datasets. One of the most popular is called GloVE (global vectors for word representation). A key part of the magic of word embedding datasets is that they are constructed so that words that are related in some semantic way have numeric embeddings that are close mathematically. For example, if "cat" = (0.15, 0.25, 0.35) then "feline" might be (0.16, 0.26, 0.36) and "rock" might be (0.98, 0.49, 0.67).
The GloVe dataset was created by an analysis of snapshot of the entire contents of Wikipedia from 2014. This means that GloVe embeddings are general in some sense. Some problems have domain specific vocabulary. For example in a medical context, the word "artery" would likely refer to a blood vessel, but in the context of transportation, "artery" would likely refer to a type of road. It is possible to create domain specific word embeddings. One popular tool or doing so is called Word2vec.
Under the Hood of an LSTM Cell
In much the same way that you don't have to know exactly how your automobile engine works in order to drive it, a knowledge of the inner workings of an LSTM cell is not necessary to create a practical LSTM network.
LSTM networks are very complex. The core component of an LSTM network is an LSTM cell. The diagram and equations in Figure 1 show two different ways to understand how an LSTM cell works.
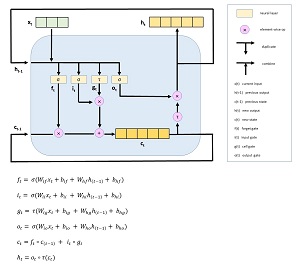 [Click on image for larger view.]How an LSTM Cell Works
[Click on image for larger view.]How an LSTM Cell Works
Notice that the cell has three inputs, indicated by arrows labelled x(t), h(t-1) and c(t-1). The x(t) represents the input at time t, which is a word in a sentence. Notice that x(t) is a vector with three cells. This means that each word is represented by an embedding of three numeric values.
The h(t) vector is the output at time t. The use of h to stand for output is historical; years ago mathematicians often expressed a function using g for input and h for output. Unfortunately, much LSTM documentation incorrectly refer to h(t) as the "hypothesis" or "hidden" state. Dealing with inconsistent and often incorrect vocabulary is a significant challenge when working with LSTM networks.
The c(t) vector is the internal cell state of the LSTM cell. It's essentially a representation of the memory of all previous input values. To recap, an LSTM cell uses the current input x(t), the previous output h(t-1) and the previous cell state c(t-1) to compute a new output h(t) and update the cell state c(t). The mechanism is truly remarkable and is not at all obvious even to highly experienced machine learning experts.
Inside the LSTM cell, the objects labelled f(t), i(t), g(t) and o(t) are called gates. You can think of them as analogous to valves in a water irrigation system. The values can be adjusted to control how much water/information is accepted and retained by the LSTM cell.
The six math equations at the bottom of Figure 1 are equivalent to the diagram in the top part of the figure. Unless you're used to dealing with math equations, they probably look very confusing. However, to an engineer with a math background, the equations are an exact blueprint and instructions for creating the underlying LSTM code.
In the equations, there are several quantities indicated by a capital W. These are weight matrices. The behavior of an LSTM cell is determined by the input value and the values of the weights.
To understand LSTM weights, consider a crude equation to predict the probability that a person is a male, like p = (0.08 * age) + (0.13 * sex) + (-0.22 * education). The age, sex and education represent input variables. The weights are 0.08, 0.13 and -0.22. Suppose age = 30, sex = 0, education = 10. Then p = (0.08)(30) + (0.13)(0) + (-0.22)(10) = 0.20 so the probability that the person is male is 0.20 and therefore you'd conclude the person is female. The weight values determine the behavior of the system.
LSTM weights are conceptually the same but there are many, many weight values (often millions) and they're stored in matrices. The values of the weights of an LSTM network are determined by using a large set of training data that has known input values and known correct output values. The weight values are iteratively adjusted until the predicted output values on the closely match the known correct output values.
Creating an LSTM Prediction System
It's rarely feasible to implement an LSTM network from scratch using a programming language. Most major neural network code libraries, such as PyTorch, TensorFlow, and Keras, have built-in LSTM functionality. These libraries are called using the Python programming language. But even so, creating an LSTM prediction system is quite challenging.
Part of the code for a simplistic sentiment prediction system using the PyTorch neural network library looks like:
def __init__(self):
# embedding_dim = 8
# state_dim = 14
# vocab_size = 27
# label_size = 3
super(LSTM_Net, self).__init__()
self.embed_layer = T.nn.Embedding(27, 8)
self.lstm_layer = T.nn.LSTM(8, 14)
self.linear_layer = T.nn.Linear(14, 3)
The embedding_dim (8) is the number of values that represent each word. The state_dim (14) is the size of the internal cell state memory, and also the output vector. The vocab_size is the total number of different words that the system can recognize. The label_size (3) is the number of possible final output values (negative, neutral, positive). In a realistic scenario the embedding_dim would be about 100, the state_dim would be perhaps 500, and the vocab_size might be roughly 10,000.
The amount of time required to create a realistic LSTM sentiment analysis system varies wildly depending mostly on the complexity of the source training data and the level of experience of the machine learning engineer. But as a very rough rule of thumb, developing a sentiment analysis system might take approximately four man-weeks.
It's Not All Unicorns
LSTM networks are just one type of a family of similar networks, all called recurrent neural networks. The term comes from the fact that the previous cell state and output values feed back into the network and are used as input values for the next word in a sentence. Although there are many types of recurrent neural networks, the two most common are LSTMs and GRUs (gated recurrent units).
LSTM networks are often extremely good at NLP problems that predict a single output, such as a sentiment of negative, positive, or neutral. But LSTM networks have been less successful at predicting multiple output values. For example, you can create an LSTM network that translates from English to Spanish. The input is a sequence of English words and the output would be a sequence of Spanish words. For such sequence-to-sequence problems, even though LSTM networks can be successful, a new type of network called attention Transformers are being increasingly used.