News
Meta's Llama 3 LLM Debuts with 8B and 70B Models
One day after Mistral released its latest open source large language model (LLM), Meta parried with its own.
"We believe these are the best open source models of their class, period," Meta wrote in a blog post Thursday announcing the launch of the Llama 3 LLM family. "With Llama 3, we set out to build the best open models that are on par with the best proprietary models available today."
The first two of the Llama 3 models, 8B and 70B (so named because of how many billions of parameters they each have) are now available to download via Meta, with availability coming "soon" to AWS Bedrock, Azure OpenAI, IBM WatsonX, Hugging Face, Google Cloud and more.
The Llama 3 models represent "major" improvements over Llama 2, according to Meta, which used over 15 trillion tokens to train 8B and 70B. Compared to its predecessor, Llama 3 was three times more efficient to train and its training data was seven times larger, containing four times more code. About 5 percent of the Llama 3 training data came from non-English sources.
Llama 3 does better at instruction, reasoning and coding than Llama 2. It also "performs well" when tested on the topics of history, STEM and various trivia.
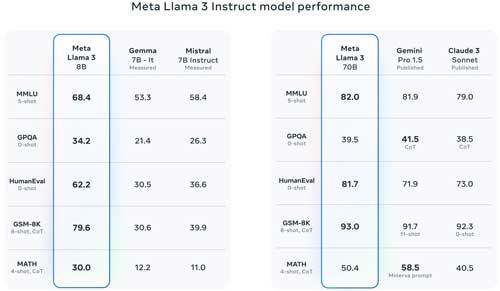 [Click on image for larger view.]
Figure 1. Llama 3's performance in various benchmark tests compared to competitors. (Source: Meta)
[Click on image for larger view.]
Figure 1. Llama 3's performance in various benchmark tests compared to competitors. (Source: Meta)
Despite all that, its inference efficiency is still "on par with Llama 2 7B," Meta said.
Under the hood, Llama 3's underlying architecture has also been upgraded from Llama 2. Per Meta:
Llama 3 uses a tokenizer with a vocabulary of 128K tokens that encodes language much more efficiently, which leads to substantially improved model performance. To improve the inference efficiency of Llama 3 models, we've adopted grouped query attention (GQA) across both the 8B and 70B sizes. We trained the models on sequences of 8,192 tokens, using a mask to ensure self-attention does not cross document boundaries.
The Meta AI chat assistant now runs on Llama 3. However, the 8B and 70B models are just the start of the Llama 3 rollout; Meta is apparently in the middle of training models with more than 400 billion parameters.
"Over the coming months," it said, "we'll release multiple models with new capabilities including multimodality, the ability to converse in multiple languages, a much longer context window, and stronger overall capabilities."