News
Mistral Releases Latest Open Source Model, Mixtral 8x22B
Generative AI upstart Mistral released its newest model this week, the open source Mixtral 8x22B, under the Apache 2.0 license.
Mixtral 8x22B "sets a new standard for performance and efficiency within the AI community," France-based Mistral said in a blog post Wednesday. "Its sparse activation patterns make it faster than any dense 70B model, while being more capable than any other open-weight model (distributed under permissive or restrictive licenses). The base model's availability makes it an excellent basis for fine-tuning use cases."
Founded just a year ago, Mistral has been riding a months-long wave of funding from major technology players, including Nvidia and Microsoft. The company's value was estimated to be approaching $2 billion by the end of 2023, though that might change to $5 billion by the end of its next funding round, according to a report this week by The Information.
Mistral produces both open source and commercial AI models. Mistral Large is its flagship commercial model while the newly released Mixtral 8x22B is, according to the company, its "most performant open model."
Mixtral 8x22B uses the "mixture-of-models" (MoE) approach, wherein different models, trained in different competencies, are applied to a dataset. MoE models are thought to be more accurate, adaptable and resource-efficient than other types of models. (A primer on the architecture of MoE models is available in this Hugging Face article.)
Because it's an MoE model, Mixtral 8x22B has "unparalleled cost efficiency for its size," according to Mistral. In MMLU (Massive Multitask Language Understanding) benchmark testing, Mixtral 8x22B was found to perform better on cost compared to other Mistral models, as well as representatives from Meta's LLaMa model family and Cohere's latest model, Command R+.
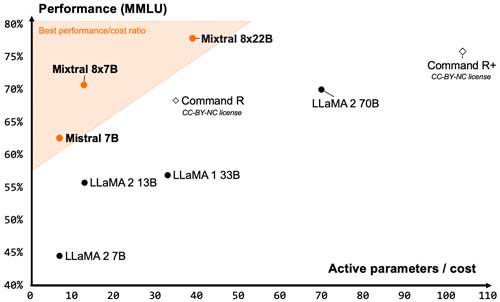 [Click on image for larger view.] Figure 1. Performance-to-cost of various AI models in MMLU testing. (Source: Mistral)
[Click on image for larger view.] Figure 1. Performance-to-cost of various AI models in MMLU testing. (Source: Mistral)
Mixtral 8x22B has a 64,000-token context window and, besides English, supports Spanish, German, French and Italian. It's also proficient at coding and mathematics, and is "natively capable of function calling."
In benchmark testing across multiple disciples, Mixtral 8x22B was shown to either outperform or perform similarly to models from Meta and Cohere.
Developers interested in Mixtral 8x22B can access it in Mistral's La Plateforme (with sign-up) here.