In-Depth
How Reinforcement Learning Is Used by Large Language Models and Why You Should Care
- By Pure AI Editors
- 06/02/2025
Large language models (LLMs) and applications that use them, such as ChatGPT, make use of a technique called reinforcement learning. Knowing how LLM reinforcement learning works allows you to understand how these language systems generate answers, and enables you to understand where and how biases, both good and bad, are introduced into the systems.
LLMs and Reinforcement Learning
An LLM like GPT-x is like a high school student who knows English grammar, vocabulary, and can look up information on Wikipedia. A chat application like ChatGPT adds technical scaffolding to a LLM in order to accept questions from a user and generate responses. Another analogy is that an LLM is like a computer CPU, and an LLM application is like a computer system with a keyboard, mouse, and monitor.
Because LLMs and LLM applications are so complex, there's no clear line separating the two components. All LLM systems, such as GPT from OpenAI, Gemini from Google, LLaMA from Meta/Facebook, Claude from Anthropic, and Phi from Microsoft, use some variation of reinforcement learning to fine-tune their systems.
LLMs generate one word after another in a probabilistic way. For example, if a current response consists of "The quick brown . . ", the LLM will likely continue constructing the response with the word "fox," and then "The quick brown fox . ." would likely continue with "jumped," and then "over," and so on.
However, after "The quick brown . . " an LLM could, with small probability, continue with "dog," which would ultimately lead to a much different response. When the sequential values generated by an LLM veer of course, it's sometimes called hallucination. LLMs control their predictability versus creativity tradeoff using a parameter setting called the temperature. Fine-tuning using reinforcement learning is needed to limit poor responses and discourage hallucinations.
Learning to Summarize from Human Feedback
Researchers from OpenAI published a paper titled, "Learning to Summarize from Human Feedback" (2020) by N. Stiennon et al., which describes a system that uses reinforcement learning to fine-tune a text summarization LLM model. The paper is available online in PDF format on several web sites. The example presented in the paper shows how to fine-tune a text summarization system, but the key ideas apply to other natural language scenarios such as question-answer, text-to-image, and topic classification.
The OpenAI researchers used a large corpus of posts from the Reddit social media platform for their experiments. One example of source text to summarize is:
We dated for about 1.5 years, and then decided to try seeing other people. There were some complications in our relationship, but we were happy while it was going.
I [18 M] recently told her [19 F] that my feelings for her were resurfacing. We talked tonight, and she said that she felt the same way, but didn't want to get back together. When I asked why, she said she didn't want her friends to judge her. She said she wants to wait a few months for them to grow on the idea, but still wants to text and talk to me like we have been doing the last week (very often, like if we were a couple).
Is she telling the truth? It seems like she is leading me on, but she doesn't seem like someone who would do that? I just need a second opinion reddit.
One of the summaries is:
"Ex and I are talking again, she says she wants to wait a few months for her friends to get used to the idea of us being together again."
A second summary is:
"Girlfriend says she loves me but doesn't want to get back together to avoid judgement, but wants to wait and get back together at a later date."
The reinforcement learning process occurs in three phases. The process is best explained by way of three diagrams.
The first phase, Human Feedback, is illustrated in Figure 1. The process starts with a source document to summarize. In reinforcement learning (RL) terminology, the part of RL that generates an answer/solution is called a policy and is usually given the symbol Greek letter pi. Several policies are used to generate summaries of the source document. Two of the summaries are selected at random and presented to a human evaluator. The human rates one of the two summaries as better.
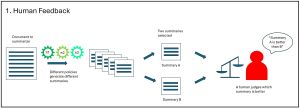 [Click on image for larger view.] Figure 1: The Human Feedback Phase
[Click on image for larger view.] Figure 1: The Human Feedback Phase
The second phase, Training the Reward Model, is shown in Figure 2. The two summaries from the Human Feedback phase are submitted to a reward function. In RL terminology, the reward function computes a numeric value for a solution generated by the RL policy, where larger values are better. The two summaries are now represented by numeric values. The two numeric reward values, and the which-is-better human judgement value, are fed to a machine learning (ML) loss function. In machine learning, a loss function computes a numeric value between two items (often denoted by script upper-case 'J'), in this case, the two summaries. The loss value is sent back to the reward function to modify it to be more accurate.
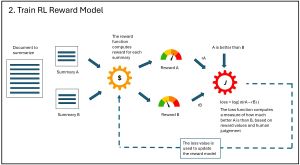 [Click on image for larger view.] Figure 2: The Reward Model Phase
[Click on image for larger view.] Figure 2: The Reward Model Phase
The third phase, Training the Policy Model, is shown in Figure 3. A new document is fed to the primary RL policy function. The policy function generates a summary of the document. The summary is fed to the reward function, which computes the reward value of the summary, where larger values are better. This is the main result. The reward value is passed back to the policy function so that it can be updated and improved.
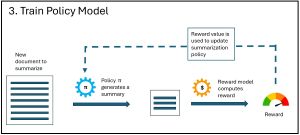 [Click on image for larger view.] Figure 3: The Policy Model Phase
[Click on image for larger view.] Figure 3: The Policy Model Phase
So What's the Point?
The Pure AI editors asked Dr. James McCaffrey, from Microsoft Research, to comment. McCaffrey noted, "When using a human-in-the-loop form of reinforcement learning, there's always a chance for some kind of bias to be introduced into the system. For example, suppose a first summary is, 'In city CCC over half of all murders are committed by BBB race males' and a second summary is, 'In city CCC over half of all murders are committed using GGG weapons.'
"Even if the first summary is clearly more accurate, a human evaluator might designate the second summary as better, based on some social engineering goal."
McCaffrey added, "In a perfect world, all AI systems would be completely transparent, including complete log files of the human feedback used to fine-tune them. But issues like these aren't in my realm of technology expertise, and so are best left to legal and business experts, with input from technical experts. In any event, all users of AI systems should be aware that different kinds of biases can be introduced into these systems."