In-Depth
Understanding Text Summarization with AI
- By Pure AI Editors
- 07/01/2024
There are many kinds of problems that are related to natural language. Some of the common problem types include question answering, text generation, data table to text and language translation. One type of natural language problem where AI is generally regarded as being at least as good as humans, and in many cases superior to humans, is text summarization. Examples include summarizing the contents of a long email message down to a couple of sentences, or summarizing the contents of a research paper to a paragraph.
The Pure AI editors asked Dr. James McCaffrey from Microsoft Research to put together a concrete example of text summarization, with an explanation intended for people who are not computer programmers -- and with an emphasis on the implications for a business that wants to implement a text summarization model.
Two Different Approaches for Text Summarization
One approach for performing text summarization is to use an AI service such as Microsoft Azure or Google Cloud Services or Amazon SageMaker. This is a high-level approach and has the advantage of being relatively easy to use.
The five main disadvantages of using an AI service are:
- Doing so locks you into the service company's ecosystem to a great extent
- It's difficult to customize the text summarization service for specialized scenarios
- Security can be an issue if sensitive information is being summarized
- AI services are mostly black-box systems where it's often difficult or impossible to know what the system is doing
- A summarization service can be pricey if large numbers of documents must be summarized
A second approach for doing text summarization is to write in-house computer programs to do so. This approach gives maximum flexibility but requires in-house programming expertise or the use of a vendor with programming expertise.
The remainder of this article illustrates the business implications of text summarization by presenting demo code. But no programming knowledge is needed to follow along.
A Demo Program
An example of a text summarization program is shown in Figure 1. The example uses the first four paragraphs of the Wikipedia article on World War I as the input to summarize. The input has 558 words. The summarization produced by the demo program is:
[{'summary_text': ' World War I or the First World War (28 July 1914 - 11 November 1918) was a global conflict between the Allies (or Entente) and the Central Powers . Fighting took place mainly in Europe and the Middle East, as well as parts of Africa and the Asia-Pacific . The causes of the conflict included the rise of Germany and decline of the Ottoman Empire, which disturbed the balance of power in place for most of the 19th century .'}]
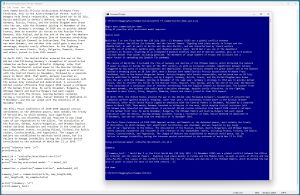 [Click on image for larger view.] Figure 1: Text Summarization Program Using a Pretrained Model Is Easy
[Click on image for larger view.] Figure 1: Text Summarization Program Using a Pretrained Model Is Easy
The demo program is remarkably short:
# hf_summarization_demo_ww1.py
# Anaconda 2023.09-0 Python 3.11.5 PyTorch 2.1.2+cpu
# transformers 4.32.3
from transformers import pipeline
print("Begin text summarization demo ")
print("Using HF pipeline with pretrained model approach ")
article = '''World War I or . . (etc.) . . World War II in 1939.'''
print("Source text: ")
print(article)
model_id = "sshleifer/distilbart-cnn-12-6"
print("Using pretrained model: " + model_id)
summarizer = pipeline("summarization", model=model_id)
summary_text = summarizer(article, max_length=120,
min_length=20, do_sample=False)
print("Summary: ")
print(summary_text)
print("End demo ")
The program is written using the Python language, which is the de facto standard for AI programs. Writing any natural language program from absolute scratch is possible, but not practical. The demo uses an open-source platform called HuggingFace. (The weird name is related to the company's origins as a social media company).
HuggingFace maintains thousands of pretrained natural language models. The demo leverages the distilbart-cnn-12-6 model, which consists of DistilBART, a base large language model derived ("distilled") from the BART model ("Bidirectional Auto-Regressive Transformers"), which is a model that is amenable to text summarization. The DistilBART language model was fine-tuned on the CNN DailyMail dataset, which consists of roughly 300,000 new articles and their summaries. The demo specifies that the summary should have at least 20 characters but no more than 120 characters.
To recap: The BART large language model understands basic English grammar and can be trained to learn how to do text summarization. BART has 406 million parameters. DistilBART is a reduced version of BART that has about 240 million parameters. The distilbart-cnn-12-6 model is the result of fine-tuning DistilBART by feeding it 300,000 news articles and their summaries, so that the model knows how to perform text summarization.
Fine-Tuning a Fine-Tuned Model
The HuggingFace platform has several pretrained models similar to distilbart-cnn-12-6. These models work well for general purpose text summarization. For scenarios with specialized documents that must be summarized, it's possible to supply additional fine-tuning with specialized training data. For example, for a company that does biomedical research, it's useful to fine-tune a text summarization model using biomedical documents.
In most scenarios, getting specialized training data is difficult. The training data must have at least several hundred items and preferably more. Each training item must have a summary, which must usually be constructed manually.
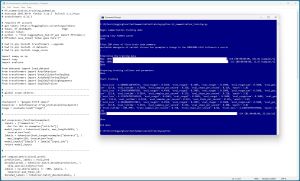 [Click on image for larger view.] Figure 2: Fine-Tuning a Custom Model for Text Summarization Is Not Easy
[Click on image for larger view.] Figure 2: Fine-Tuning a Custom Model for Text Summarization Is Not Easy
Fine-tuning a fine-tuned model is much, much more difficult than using an existing pretrained model. The screenshot in Figure 2 shows an example where the T5-small base model (similar to DistilBART) is being fine-tuned using medical data from the PubMed dataset.
Wrapping Up
Dr. McCaffrey offered an opinion, "I think for most organizations and most text summarization scenarios, using an existing large language model that has been trained using general purpose data, such as news articles, is relatively simple and effective. The most difficult part of deploying a text summarization system will likely be integrating the system with other systems in the organization."
McCaffrey added, "On the other hand, fine-tuning a pretrained model with domain-specific data is much more difficult than might be expected. Most of the time and effort will be directed at preparing the summary part of the training data, which must be done manually in most cases."