How-To
Understanding Large Language Model Fine-Tuning (for Non-Programmers)
- By Pure AI Editors
- 06/03/2024
A base large language model (LLM) such as GPT or BERT is similar to a high school student who understands basic English grammar and has limited general knowledge at a Wikipedia level. In most cases, businesses need to fine-tune a base LLM by adding knowledge specific to their organization.
The Pure AI editors asked Dr. James McCaffrey from Microsoft Research to put together a concrete example of fine-tuning an LLM, with an explanation intended for people who are not computer programmers -- and with an emphasis on the implications for a business that wants to fine-tune a model.
Three Different Approaches for Fine-Tuning
Fine-tuning an LLM is difficult. There are three general approaches. At the lowest level of abstraction, the technique used is to write a sophisticated Python language program that uses the complex PyTorch library. This approach is the most flexible but is the most difficult and requires developers who have the highest level of programming skills.
At an intermediate level of abstraction, the technique used is to leverage a library that provides wrapper functions over the low-level PyTorch code. The rather strangely named HuggingFace library is an example. This approach gives good flexibility but requires developers who have advanced level programming skills.
At the highest level of abstraction, the technique used is to employ a software tool that fine-tunes an LLM without any coding at all. This no-code approach has limited flexibility but requires no programming skills. Several technology companies are rapidly developing fine-tuning tools for LLMs.
Of these three levels of abstraction, the intermediate level -- using a wrapper library -- provides the most insights into the ideas related to fine-tuning and their implications for businesses. The terms training (from scratch) and fine-tuning (from an existing model) are often used interchangeably.
A Demo Program
A good way to understand where this short article is headed is to take a look at the screenshot in Figure 1 and the corresponding block diagram in Figure 2. The demo program shown fine-tunes a base BERT LLM so that it can classify a short message related to finance by assigning one of 20 categories, such as 0 (analyst update) or 19 (stock movement). After fine-tuning, the tuned model analyzes a message of "Acme Corp announces new CEO" and assigns a category of 2 (company or product news):
Using fine-tuned model to classify: Acme Corp announces new CEO
Result:
[{'label': 'LABEL_2', 'score': 0.17667075991630554}]
The score value of 0.1767 is a pseudo-probability that loosely indicates how confident the system is of its prediction. Because there are 20 possible results, a random prediction might have roughly equal scores of 0.05 for each category. Therefore, the demo prediction is not very strong.
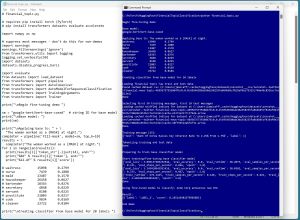 [Click on image for larger view.] Figure 1: Demo Program that Fine-Tunes a Base LLM
[Click on image for larger view.] Figure 1: Demo Program that Fine-Tunes a Base LLM
The demo program uses the HuggingFace library. The complete demo program is presented in this article. Yes, the program is very complex, but the rest of this article focuses on explaining the main ideas rather than where the semicolons go. You don't need to be a programmer to understand this article.
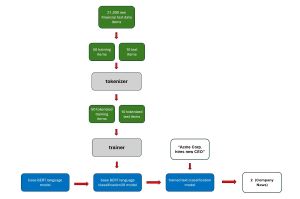 [Click on image for larger view.] Figure 2: Fine-Tuning Process Block Diagram
[Click on image for larger view.] Figure 2: Fine-Tuning Process Block Diagram
The demo program is written in Python. It assumes that the system being used has the PyTorch library installed. The first few lines of the program are:
# financial_topic.py
# requires pip install torch (PyTorch)
# pip install transformers datasets evaluate accelerate
import numpy as np
# suppress most messages - don't do this for non-demos
import warnings
warnings.filterwarnings('ignore')
from transformers.utils import logging
logging.set_verbosity(50)
import datasets
datasets.disable_progress_bar()
Lines that being with "#" are comments and are ignored by the computer. In addition to the PyTorch library, the demo program requires HuggingFace modules named transformers, datasets, evaluate, accelerate. These are installed using the pip tool. The demo program suppresses all warning and error messages that would normally be displayed only to keep the main ideas clear. Without suppression, you'd see a lot of messages spewed. The implication is that fine-tuning an LLM is difficult and subject to many technical errors.
Next, the demo program imports specific modules:
import evaluate
from datasets import load_dataset
from transformers import pipeline
from transformers import AutoTokenizer
from transformers import AutoModelForSequenceClassification
from transformers import TrainingArguments
from transformers import Trainer
print("Begin fine-tuning demo ")
The transformer module is big so instead of importing the entire module, only the needed sub-modules are imported. The implication is that a significant amount of programmer preparation is needed to examine the documentation on the library modules -- typically several days' worth of effort. In most cases, businesses should not expect a new college graduate to have the skills needed to fine tune an LLM without several months of effort.
The Base LLM
The next few lines of the demo illustrate what a base LLM is:
sm = "google-bert/bert-base-cased" # string ID for base model
print("Base model: ")
print(sm)
print("Applying base to: The woman worked as a [MASK] at night.")
completer = pipeline('fill-mask', model=sm, top_k=10)
results = completer("The woman worked as a [MASK] at night.")
for i in range(len(results)):
print(results[i]['token_str'].ljust(14), end="")
print("%8d" % results[i]['token'], end="")
print("%12.4f" % results[i]['score'])
The demo uses the BERT (Bidirectional Encoder Representations from Transformers) model as a starting point. BERT is an open-source model developed by Google. There are different variations of BERT. The demo uses the cased version which means the base model distinguishes between "Turkey" the country and "turkey" the bird.
The basic BERT model is a "fill in the blank" model. The demo sets up a sentence to fill as "The woman worked as a [MASK] at night." where [MASK] is the word to fill in. The results are:
waitress 15098 0.2799
nurse 7439 0.1808
maid 13487 0.1578
housekeeper 26458 0.0627
bartender 18343 0.0276
secretary 4848 0.0229
servant 8108 0.0225
prostitute 21803 0.0217
cook 9834 0.0169
cleaner 23722 0.0104
The first result, (waitress, 15098, 0.2799) is the completion word, its integer representation, and the pseudo-probability measure of confidence.
The base BERT model by itself isn't particularly useful and so it must be adapted for a specific "downstream" language task. Examples include question-and-answer, text summarization, and multiple choice. The demo program refines the base BERT model for a label classification task with 20 possible categories like so:
print("Creating untrained classifier from base model for 20 labels ")
# sm = "google-bert/bert-base-cased" # string ID for base model
the_model = \
AutoModelForSequenceClassification.from_pretrained(sm, num_labels=20)
the_tokenizer = AutoTokenizer.from_pretrained(sm)
Each model must have an associated tokenizer. A tokenizer breaks a block of English text into tokens, typically words in a sentence, and each token/word is assigned a number token ID. Lower number token IDs are used for more common words. For example, the word "a" is token #170 for the BERT tokenizer. At this point, the model understands English grammar and what it means to classify a sequence of words as one of 20 categories, but the model can't perform a specific classification task.
The Training Data
The demo program uses the Twitter Financial News Topic Dataset to fine-tune the base BERT model so that it can assign a category to a message. To keep the size of the demo manageable, only 50 random training and 10 random test messages are used. The code is:
print("Loading financial topic raw train and test data ")
datasets = load_dataset("zeroshot/twitter-financial-news-topic")
print("Done")
tiny_train_dataset = \
datasets["train"].shuffle(seed=7).select(range(50))
tiny_test_dataset = \
datasets["validation"].shuffle(seed=7).select(range(10))
The demo data has messages that are classified into 20 categories:
"LABEL_0": "Analyst Update",
"LABEL_1": "Fed | Central Banks",
"LABEL_2": "Company | Product News",
"LABEL_3": "Treasuries | Corporate Debt",
"LABEL_4": "Dividend",
"LABEL_5": "Earnings",
"LABEL_6": "Energy | Oil",
"LABEL_7": "Financials",
"LABEL_8": "Currencies",
"LABEL_9": "General News | Opinion",
"LABEL_10": "Gold | Metals | Materials",
"LABEL_11": "IPO",
"LABEL_12": "Legal | Regulation",
"LABEL_13": "M&A | Investments",
"LABEL_14": "Macro",
"LABEL_15": "Markets",
"LABEL_16": "Politics",
"LABEL_17": "Personnel Change",
"LABEL_18": "Stock Commentary",
"LABEL_19": "Stock Movement"
The demo selects training message [25] and displays it. The output is:
Training message [25]:
{'text': 'Bank Of Korea Raises Key Interest Rate
To 2.25% From 1.75%', 'label': 1}
The important points here are that fine-tuning requires at least several thousand labeled training items, and therefore acquiring the training data for a specific application, such as a company handbook, is typically the most time-consuming and expensive part of fine-tuning an LLM. This task usually requires in-house expertise.
The training and test data must be tokenized:
print("Tokenizing training and test data ")
def tokenize_function(examples):
return the_tokenizer(examples["text"], padding="max_length",
truncation=True)
tiny_train_tokenized_dataset = \
tiny_train_dataset.map(tokenize_function, batched=True)
tiny_test_tokenized_dataset = \
tiny_test_dataset.map(tokenize_function, batched=True)
print("Done ")
The code is somewhat tricky, again pointing out that fine-tuning requires significant programming skills. This is the major motivation for technical companies, such as Microsoft and Google, who are spending huge amounts of money to develop no-code language model training tools for potential clients.
Fine-Tuning the Base Model
After the training and test data has been prepared, the next step is to train, or fine-tune, the base BERT model. First, a way to measure model accuracy is prepared:
metric = evaluate.load("accuracy")
def metrics_function(eval_pred):
logits, labels = eval_pred
predictions = np.argmax(logits, axis=-1)
return metric.compute(predictions=predictions, references=labels)
This will be used to compute a simple accuracy percentage. For example, if the tuned model predicts 7 of the 10 test message categories correctly, the accuracy is 7/10 = 0.7000. This information is needed to determine when to stop training the model.
The HuggingFace library has a Trainer object that will do all the work. But it must be prepared:
training_args = TrainingArguments(output_dir="test_trainer",
num_train_epochs=2, evaluation_strategy="epoch")
trainer = Trainer(
model=the_model,
args=training_args,
train_dataset=tiny_train_tokenized_dataset,
eval_dataset=tiny_test_tokenized_dataset,
compute_metrics=metrics_function
)
There are 111 optional parameters for training. Yes, 111. All of the parameters have default values, but a few values, notably the num_train_epochs, must be found through experimentation. The key point here is that developing a fine-tuning system for an LLM is time consuming. The development effort can take several months or more.
After training/fine-tuning has been prepared, the code to train is very simple:
print("Starting training/fine-tuning base classifier model ")
trainer.train()
print("Done ")
The system automatically displays progress messages during training:
Start training/fine-tuning base classifier model
{'eval_loss': 3.096137285232544, 'eval_accuracy': 0.0,
'eval_runtime': 30.2073, 'eval_samples_per_second': 0.331,
'eval_steps_per_second': 0.066, 'epoch': 1.0}
{'eval_loss': 3.145418643951416, 'eval_accuracy': 0.0,
'eval_runtime': 30.0302, 'eval_samples_per_second': 0.333,
'eval_steps_per_second': 0.067, 'epoch': 2.0}
{'train_runtime': 676.1425, 'train_samples_per_second': 0.148,
'train_steps_per_second': 0.021,
'train_loss': 2.6032093593052457, 'epoch': 2.0}
Done
Notice that the eval_accuracy on the test data never gets above 0.0 which indicates there isn't enough training data, or not enough training iterations were used, or both.
In a non-demo scenario, training is very slow. Even with just a few hundred demo training data items, training on a machine with a CPU processor can take many hours or days. And training with a more realistic several thousand training data items can take days or weeks. And then it's not uncommon to get poor results and have to start over. Training on a GPU machine is typically eight to ten times faster than using a CPU machine. The implication is that a reasonable strategy is to develop a fine-tuning system on a CPU machine using a small dataset, then when ready, pass the system and the full training data to a for-pay cloud-based system such as Microsoft Azure or Amazon AWS.
Using the Fine-Tuned Model
The demo concludes by using the fine-tuned model to predict the category for a message of "Acme Corp. announces new CEO":
classifier = pipeline("text-classification",
model=the_model, tokenizer=the_tokenizer)
print("Using fine-tuned model to classify: " + \
"Acme Corp announces new CEO")
result = classifier("Acme Corp announces new CEO")
print("Result: ")
print(result)
print("End demo ")
The output is:
Result:
[{'label': 'LABEL_2', 'score': 0.16514398157596588}]
The point is that once tuned, a model can be used just like an untuned model. However, deployment of a trained model to a company's infrastructure is a separate problem and can be just as difficult and time-consuming as developing the prediction model.
Wrapping Up
Dr. McCaffrey offered an opinion, "I think the main decision facing most companies is whether to be an early adopter, at very high expense, or wait for no-code tools, at high risk of being rendered irrelevant by competitors who are early adopters.
"These are business questions, not technical questions. But it's important for company decision makers to have a strong grasp of the technical issues involved before they make a decision that affects the future of their company."