In-Depth
Few-Shot, One-Shot, Zero-Shot and Fine-Tuning for Not-Quite Dummies
We asked a data scientist to explain the terms in enough detail to provide useful information, but not so much detail to make your head explode.
- By Pure AI Editors
- 05/01/2024
You may have heard or read the phrase "fine-tuning a large language model." Even AI experts are sometimes confused by the closely related terms few-shot learning, one-shot learning, zero-shot learning and fine-tuning. The confusion is due in part to the fact that there are no universally agreed-upon definitions for the terms. All four terms represent important ideas in AI.
The terms all refer to specific kinds of general "transfer learning" where the goal is to start with an existing AI model and adapt it for use on a new problem. The Pure AI editors spoke to Dr. James McCaffrey from Microsoft Research and asked him to explain the terms in enough detail to provide useful information, but not so much detail to make your head explode.
1. Few-Shot Learning
Few-shot learning usually applies to image classification. The goal is to classify an image when you only have a few (perhaps a dozen or fewer) examples of each class of labeled data. For example, suppose you have an existing trained model that can classify hundreds of different types of animals, and then your system acquires just five images of a new previously unseen type of animal, such as an axolotl.
One of many possible techniques for few-shot learning is to generate hundreds of variations of the five new images (by stretching, horizontally inverting, etc.), add them to the original training data, and then retrain the model. A second technique is to compute similarity scores between the image to classify and the small set of labeled images. A third, more sophisticated approach, for few-shot learning is called "model agnostic meta-learning" (MAML), where a base model is designed specifically so that new classes can be trained quickly and easily without having to retrain the model from scratch.
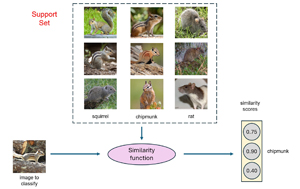 [Click on image for larger view.] Figure 1: Few-Shot Learning Using a Similarity Function
[Click on image for larger view.] Figure 1: Few-Shot Learning Using a Similarity Function
2. One-Shot Learning
One-shot learning usually applies to image classification. The goal is to classify an image when you only have exactly one example of each class. For example, a bank may have just one example of each customer's signature on file and a new signature on a receipt must be classified as authentic or fraudulent. One common technique for one-shot learning is to use a neural network that has what's called Siamese network architecture.
 [Click on image for larger view.] Figure 2: One-Shot Learning Using a Siamese Network
[Click on image for larger view.] Figure 2: One-Shot Learning Using a Siamese Network
One-shot learning can be considered an extreme form of few-shot learning. However, the techniques for few-shot learning tend to be different from the techniques for few-shot learning, and so a distinction is usually made between the two ideas.
3. Zero-Shot Learning
Zero-shot Learning often applies to image classification. Even though the term "zero-shot learning" looks and sounds similar to the terms "one-shot learning" and "few-shot learning", zero-shot learning is significantly different.
The goal is to classify an image using an existing model that has never been trained on the image -- you have zero labeled images. For example, suppose you have an existing trained model that can classify hundreds of different animals (horse, cougar, etc.), plants (iris flower, dandelion, etc.), colors, and so on, but you need the model to classify a new previously unseen animal that happens to be a leopard.
The problem seems impossible because there's no way to create new knowledge out of thin air. One common technique for zero-shot learning is kind of a cheat: Instead of training or retraining the existing model directly, you incorporate an auxiliary set of textual information such as "a leopard looks like a cougar that has spots." The auxiliary text information connects existing images and allows the model to identify a leopard.
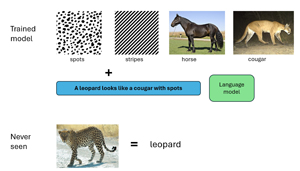 [Click on image for larger view.] Figure 3: Zero-Shot Learning
[Click on image for larger view.] Figure 3: Zero-Shot Learning
Notice that one-shot learning, few-shot learning and zero-shot learning typically (but not always) apply to image classification problems. This means the terms are rather narrowly focused on image recognition systems.
4. Fine-Tuning
Fine-tuning often applies to language models. The goal is to start with a pre-trained large language model such as GPT-3 that understands basic English grammar and knows general facts from Wikipedia, and add specialized information such as flight information for an airline company, or chemistry information for a pharmaceutical company.
A not-so-good strategy for fine-tuning is to prepare new specialized training data then completely retrain the base model, changing all of the billions of parameters/weights (GPT-3 has 175 billion). Because large language models are huge, they are difficult and expensive to retrain. This constraint has led to researchers looking at small language models that can act as a base and be retrained for specialized knowledge. Small language base models can also be deployed on smaller devices, possibly as small as phones.
A better strategy than completely retraining a large language model is to prepare new specialized training data and then train the base model in a way that changes only the last one or two layers of parameters. An even better approach is to leave the base model alone and use the specialized training data to create a new layer (or a few layers) that can be appended to the base model. This last approach allows you to maintain just one large base model, and many relatively small modules (a few million parameters) for specialized tasks.
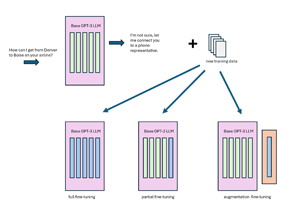 [Click on image for larger view.] Figure 4: Different Approaches for Fine-Tuning a Large Language Model
[Click on image for larger view.] Figure 4: Different Approaches for Fine-Tuning a Large Language Model
Wrapping Up
Language model fine-tuning is one of the most active areas of AI research. McCaffrey commented, "One vision is to create a huge AI ecosystem made from one large base language model plus dozens of small modules with specialized information. These agents can communicate with and learn from each other to create extremely powerful systems. If enough of such systems can be combined, the goal of general AI will likely be one step closer to reality."
He added, "One of my colleagues, Ricky Loynd, noted that a relatively new development is called continual agent learning, where a software agent that learns-to-learn over its lifetime, so that it can eventually learn very quickly from its own experience."
McCaffrey concluded, "As recently as several months ago, fine-tuning a large language model was an extremely difficult task. But software support tools for fine-tuning are being released very quickly. It's likely that creating a custom, fine-tuned AI assistant will soon be feasible for many businesses and maybe even individuals."