In-Depth
AI's 'Year of Practicality': Conversation with Data Scientist Cameron Turner
Is this the year AI grows up? How are enteprises today actually using generative AI? And what do tech vendors really mean when they call an LLM "private"?
In the span of two years, generative AI has gone from pop culture novelty to the next potential trillion-dollar market.
Analyst firm Gartner has perhaps a more grounded perspective on the technology's maturity by way of its oft-cited "Hype Cycle." According to Gartner, generative AI isn't quite ready for primetime; as of last August, it was still at the zenith of the "peak of inflated expectations," the period of a buzzy technology's lifespan when lofty promises collide with mixed to middling results. By this measure, it'll be five to 10 years before generative AI reaches the "plateau of productivity," the period when a technology's ubiquity matches its utility. In other words, when the hype finally matches reality.
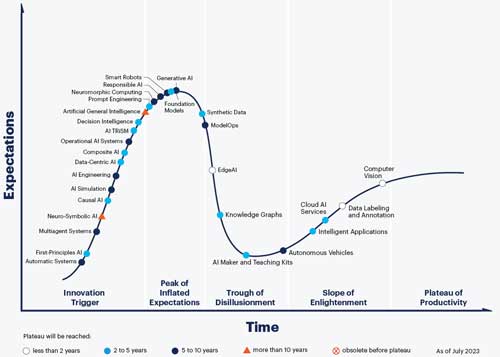 [Click on image for larger view.]
Gartner's Hype Cycle for AI, August 2023
[Click on image for larger view.]
Gartner's Hype Cycle for AI, August 2023
Not that generative AI adoption has been slow; far from it. In a late-2023 O'Reilly survey of nearly 5,000 enterprise executives, over two-thirds reported using generative AI in their businesses already. "We've never seen a technology adopted as fast as generative AI," the survey's writers said.
Somewhere between Gartner's temperance and O'Reilly's bullishness is Cameron Turner, career data scientist and current vice president at global digital transformation consultancy Kin + Carta. Through his work, Turner has seen firsthand and in real-time how generative AI has started to embed itself in the enterprise IT landscape. He spoke recently with Pure AI about AI's progress, its limitations and its future in business; below is our conversation, edited for brevity and clarity.
Pure AI: So, we've spoken twice now. The first time, the enterprise was still at the skepticism and caution stage when it came to generative AI. Then, when we spoke last year, the environment was more exploratory and we talked about what things companies should start setting in place. What's your take on what this year means for AI? Is this "year zero" for generative AI, when it truly becomes part of the enterprise IT toolbox?
Turner: Since we've spoken, I think the world's changed quite a bit and adoption has occurred. I think the surprise, at least for me, is that it hasn't been something that is completely comprehensive. Rather, [AI has] become an instrument, one tool in the toolbox and part of larger programs.
But there's really not anything that we're doing now that doesn't touch on generative AI in some way. You can call 2024 "year zero" but also "the year of practicality," where we're moving beyond grand visions and statements about massive disruption...and into some real hands-on adoption, and taking dependencies on generative AI and LLMs in production workloads.
What are some examples you've seen of people using generative AI in business, beyond just content creation?
I think what's exciting right now is that the use cases are directly aligned to critical business problems. ... There have been problems with AI workflows from the beginning that, it turns out, generative AI was really helpful for. For example, data cleansing, understanding data quality and doing assessments. Conversion of unstructured data and unstructured data is one that...is definitely deployed to production now. We're seeing a lot of instances where that's the primary use case -- taking all [of an organization's] images, video, audio and language content and converting that into structured data that can then be used for good, old machine learning with "traditional AI," I guess you'd call it now.
What that enables people to do is interact with their data. That's a different use case. [Generative AI lets businesses] turn what used to be a request to run a single query that was run overnight and returned in a spreadsheet that you would work off of [into] literally chatting with your data and getting answers to your questions and doing an exploration without necessarily needing knowledge of SQL. That's another scenario that we're seeing a lot of.
Are data security concerns still as big of a hurdle to business adoption as they were at the start?
Another thing that's gone mainstream is the private hosting of public LLMs. In Azure, you can access GPT-4 and feed it your data but not have any of that data become a part of the training process for GPT-5. ... I think that was the big unlock because that was where the anxiety was running. Previously, you had a workforce that saw the power of being able to do...really contextual QA of their own data, but at the cost of actually overloading the prompts with private data that would then be sitting in a public server, which is not acceptable for pretty much everyone's data policy. Now that we have that solved [with privately hosted public LLMs], I think that is a really big deal.

"You can call 2024 'year zero' but also 'the year of practicality,' where we're moving beyond grand visions and statements about massive disruption and into some real hands-on adoption."
Briefly, can you explain what is meant by a private LLM? I've heard different definitions from different vendors.
It's a great question because there's a lot of confusion in the market right now. [With a private LLM] you can do everything from create your own LLM from scratch using your own data corpus, to extend existing LLMs with your data, to fine tuning to prompt engineering. So there are these steps in terms of what you can do with what we would consider to be a private LLM.
The key point from the physical side, though, is that there is no crossing the brain-blood barrier. This is my private data corpus, but I can leverage all of the work that's been done to train that [public] model...and then extend it with my own data at very low cost. I can leverage everything that's enabled through a vector-based approach in order to get the best answers, against my smaller data that I'm attaching to it. So there are different ways to architect it.
That sounds like private LLMs will become the default by necessity, rather than a nice-to-have.
For the most part, until you get to very large datasets in specialized areas, there's not a need to go and train your own LLM from scratch. But that may change. There's a lot of interest in the market around creating smaller LLMs that are more easily trained in order to solve specific problems.
I think what we'll see in the next 10 years are small LLMs for certain problems, as I said, but also potentially consortiums. This is something that has been talked about for a long time -- an industry consortium where it's pay-to-play to basically get your data into a data commons. And from that data commons, you're able to extract and you can have even competitors. But there haven't been a lot of great examples of that because there are competitive issues and, of course, data privacy issues and other things.
Are you finding organizations getting better at prompt engineering, or is that still fairly specialized?
There is a way of talking to generative AI that will yield better results, especially when you're working on specialized scenarios. [That entails] providing guidance, overloading prompts with templates of ideal responses, and then, as much as possible, working toward your output that can then be validated.
We're a consulting shop, so we always find ourselves in between the client and the platforms and technologies. For us, prompt engineering is a great example where there's an intent, there's the technology, and then there's that space in between. One of the things that we have done and will continue to do is build in that middle layer. For example, if I asked my data, "What were the top selling products in the last quarter?" That middle layer would need to interpret and sort of decorate that request with the correct knowledge and be able to know, "The person who asked about top-selling products sits in this department, so they're interested in these products. They are on a fiscal year that ends in June, so when they say, 'last quarter,' it's not necessarily a calendar-year purchase." All of that. That middle layer stuff becomes a part of the prompt. And there's real software work to do there in order to build up that interpretation.
"Everything points back to data quality. A lot of the heavy lifting in all of our projects tends to be around getting data resources into a position where they can be exploited and capitalized on. That requires getting the house in order and having good data foundations."
Are you then also finding that you need to help companies do the data standardization that we talked about earlier? Or is that something that they're mostly using themselves?
That is an awesome question because I think it points to the fact that...everything points back to data quality. A lot of the heavy lifting in all of our projects tends to be around getting data resources into a position where they can be exploited and capitalized on. That requires getting the house in order and having good data foundations, including governance, understanding provenance, being able to understand stewardship, as well as thinking about the engineering piece, like model drift and what can happen when people start to act on the output of these models and then that output becomes part of the training data again -- the echo chamber effect. ... If you just throw LLMs at your data corpus without going through that exercise of understanding, you can have erroneous output.
And that way disaster lies?
It's not a killer for the scenario. And it's inevitable, in a way. I grew up on Microsoft Office, and I remember in the late '90s people saying, "No way should anyone ever create their own presentation, that will be terrible. You have to have the graphics department do it for you." And the same for Excel. "You shouldn't have the citizen, some corporate person, creating spreadsheets. That should really be on the people who are in accounting. They do that." We've democratized these scenarios. AI is another scenario that's being democratized.
What do you think is the next big AI milestone? There's a lot of talk about AGI [artificial general intelligence] right now. Is that something that you see bearing out in a landmark way in the next couple of months?
AGI is a broad term, but if you think about what's required in order to enable that, it's an unbounded data corpus. You don't have any limitations. [By comparison,] as a human, I can draw on my experience, my personal life, my professional life and all those things. But [an unbounded data corpus] is a core requirement for AGI. And the challenge with our data systems today is that we necessarily have to create hard barriers in terms of how and what data can be used in the context of those systems.
In terms of the next big thing, something that I'm really passionate about is what we could potentially do with data synthesis with ethical AI in order to correctly balance the signal that goes into these systems, and also do a good job of anonymization. So we can take out PII [personally identifiable information] and PHI [personal health information]. We can develop systems that are fully compliant to GDPR, CCPA and other [data privacy] standards out there. All of those are really blunt tools that just cut out the availability of data for use in AI. If we can solve for that and create a dataset that has all the signals of the original data but none of the scary stuff -- like PII or bias, which has historically existed in the data -- then we have an opportunity to really expand the canvas of the data that's used in order to train AI. That's where I think we get to some really interesting new use cases.