AI Test Lab
Do AI-Generated Content Detectors Actually Work?
For the inaugural post in our AI Test Lab column, we put AI content detectors to the test against both original essays and AI-generated content to see how well they can tell human-generated text from that created by machines.
By now, everyone's heard of AI content detectors; whether you've read stories about teachers using them to detect AI-written essays, threads discussing their viability or seen ads selling them online, there's a number of options available that say they can determine (to a degree) if content is human- or AI-written.
So how well do these services really work? As a whole, are they reliable? Do they throw a lot of false positives? Negatives? How much variance is there between the various services? Is content output by the various AI-generators (GPT 3.5, GPT 4, Bard) easier/harder to detect?
Below is what we found. Some notes before we start, however:
- The purpose of this article isn't to put individual systems to the test; rather, it's to look at the technology as a group, and see how reliable in general they are at determining if a piece of content was written by a person or AI.
- All of this is new technology and changing rapidly, so individual test outputs are merely a snapshot in time. We have no way of knowing how replicable these results will be at any other point in time.
- Every AI generator says that you shouldn't rely on this technology solely when trying to determine if a student cheated; we agree wholeheartedly. Again, this article isn't about using this technology to say if someone cheated or not. It's about looking at how this technology works against the particular samples we fed these systems.
With all that said, let's get started.
About the Content Tested
We decided to test with 12 pieces of content total: four original essays written 100 percent by humans and eight written 100 percent by AI (a mix of ChatGPT 4, ChatGPT 3.5 and Bard). A visual summary of the content is in the graphic below:

Feel free to skip the rest of this section if you don't want more details on the content used for testing; or, alternatively, feel free to go here if you want to actually see the essays used in full.
For the original content, we solicited original essays from friends and family members. The first three were chosen based on a mix of factors, including different writing styles, length and whether they had sources (this ended up not making a difference; we tested with and without sources and it didn't dramatically impact scores, if at all). For the fourth original essay, when doing background research for this article, we ran across rumblings online that original writing published on the Internet that may have been scraped into ChatGPT's training data could throw up false positives -- for example, it's rumored the U.S. Constitution previously came up positive as AI-written by at least some test tools for a while. So we wanted to have one original essay we knew had been published on the Internet and very well could have been scraped for ChatGPT training data. To that end, for the fourth original essay, we chose a "Sparknotes" example essay on Tom Sawyer. This essay was also chosen as it was shorter than the other example original essays, at only 612 words.
For the AI-generated essays, we started with four ChatGPT 4-generated essays of varying lengths, with and without sources, on a variety of topics (from Shakesphere to the History of Laos in the 1970s). We then created two essays with ChatGPT 3.5 and one with Bard, and then we had ChatGPT 4 rewrite one of the ChatGPT 3.5 essays, as there was discussion online that this is a way to "fool" the AI detectors.
Some additional notes on the AI-generated essays:
- All AI essays were generated in late June 2023; the actual testing took place in early July 2023.
- Not all are "one-shot" generations (in fact, most are not). In some instances, we went back and asked AI to be more fluid or, for longer essays, to expand on sections, and then pieced the content together (this technique was generally required to achieve longer output).
- Accuracy of the output was not considered or even looked at beyond seeming generally correct, as accuracy is not something the automatic detectors review, only writing style.
- Edits made to the output were extremely minimal but are ones that any user may make: e.g., removing unneeded subheads like "conclusion" and making formatting changes. No other rewrites were made.
- Text was taken from the AI generators, pasted into Notepad, then pasted in Google Docs before putting into the AI detectors, in part to remove any possibility of unique encoding of characters that may be present in the AI-generation output; we wanted the detection to be based on the content-only. Plus, this is how most people testing essays are using these services -- most would not input directly from the generator, so we wanted to mimic real-world use.
About the Systems Tested
As mentioned above, we wanted this article to examine the genre of AI detectors as a whole, so we chose a mix of paid and free services (and combined some free services results, as many offered the exact same output; more on this later in this article). Also, we would have loved to have included Turnitin -- a common system used by educators and paid by school districts -- in our testing, but there is no way to access the tool without an enterprise account.
Also, for many of the systems, there is nothing to indicate that the free and paid levels generate different quality output; generally, the difference is in how much more text they can accommodate. However, whether the free or paid tier was used for this article is noted below, in case it (unbeknownst to us) made some sort of difference.
The tools we ended up testing are:
- GoWinston.AI (free tier; paid starts at $12 per month, used-paid version)
- GPTZero.me (free tier; paid starts at $9.99 per month, used-paid version)
- AI Text Classifier (free tool from OpenAI, the maker of ChatGPT)
- (Many) Free Testing Tools (more on why these are combined below)
- Passed.AI (free, plus paid tiers; users can buy more credits; used $9.99 tier and paid for more credits to complete scan of all content for this article)
At the end of this article, you'll see a chart with the combined results, but first we'll break down each service individually, as each one scores writing in different ways, and so the detection "passes" and "fails" have to be individually defined by the service. As to what constitutes a "pass" or "fail," we know in some ways this could be seen as arbitrary, so while we think we picked decent criteria, below we've broken down how we decided what a pass or fail is so that you can make your own judgements.
Note that we went into the testing completely blind; we did not pre-test any of the content or the systems.
GoWinston.AI
For GoWinston, every essay is given a percentage "likely written" score, from 100% likely human-written to 100% likely AI-written.
As this was the first system we tested, we used this to help us set our testing baselines. We decided that for the original essays, anything less than 75% for human-witten would be a fail (if you wrote a 100% original essay, you'd probably be annoyed if a service wrongly said that it had more than a 25% likelihood of being AI-generated). For the AI-generated content, we decided that fails would refer to when the system said a computer-written essay was more than 50% likely to be written by a human.
With these in mind, here's how GoWinston.AI did:

Each percentage shows how likely Winston thought the essay was written by a human. Based on the criteria we set above, the service did pretty well, only missing three of the 12, and two of them by a very small margin (70 vs. 75, and 52 vs. 50). Also, it seems clear that when it knows something was AI-written, it gives an extremely low score, so it does seem like those using it to judge students' papers could get away with only suspecting those with an extremely low output score, if one had to have a definitive line.
GPTZero.me
This is one of the most popular and well-respected free detectors on the market; we upgraded to the paid tier only because it appeared to make the interface slightly easier to use, and as it's pitched to educators, we figured perhaps more educators would be using this tier as it's designed to handle volume.
In any case, GPTZero doesn't give percentage scores (like Winston), but instead gives text ratings of "Likely Entirely By Human," "May Include Parts By AI" and "Likely Entirely by AI" (there may be other outputs, but these are the only three we encountered). So for its pass/fail criteria, we decided that:
- Original Essays: "Likely Entirely By Human" would be a pass; anything else would be a fail.
- AI-Generated Essays: "May Include Parts By AI" and "Likely Entirely by AI" would be a pass; anything else would be a fail.
Here's how it did with our sample essays:
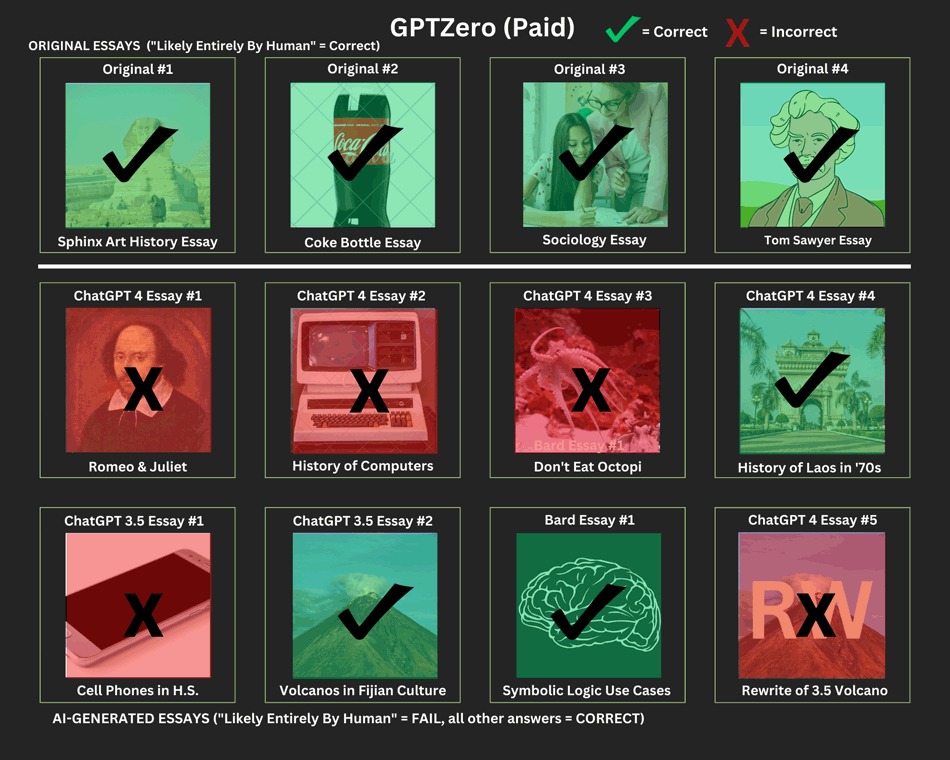
It correctly identified all the original essays as human-written; it appears that GPTZero has less of a chance of encountering false flags on original content. However, it appeared to struggle with the AI-generated content, especially those generated by ChatGPT 4, although it is interesting that it was able to flag the "History of Laos in the '70s" essay as AI-generated when that was one of the ChatGPT4 essays that Winston incorrectly classified as human-written (with a score of 93% likely).
AI Text Classifier
AI Text Classifier is a free tool published by OpenAI, the makers of ChatGPT. It was launched in January 2023; ChatGPT 4 went live in March 2023. We don't really know what models it's been trained on or for; the output, like GPTZero, is given in text format, and ranges from "very unlikely AI-generated" to "very likely AI-generated." We decided that fails for original content would be if the system said it was "likely" or "very likely" AI-generated, and fails for AI content would be if the system said it was "very unlikely" or "unlikely" AI-generated.
Here's how this system did:
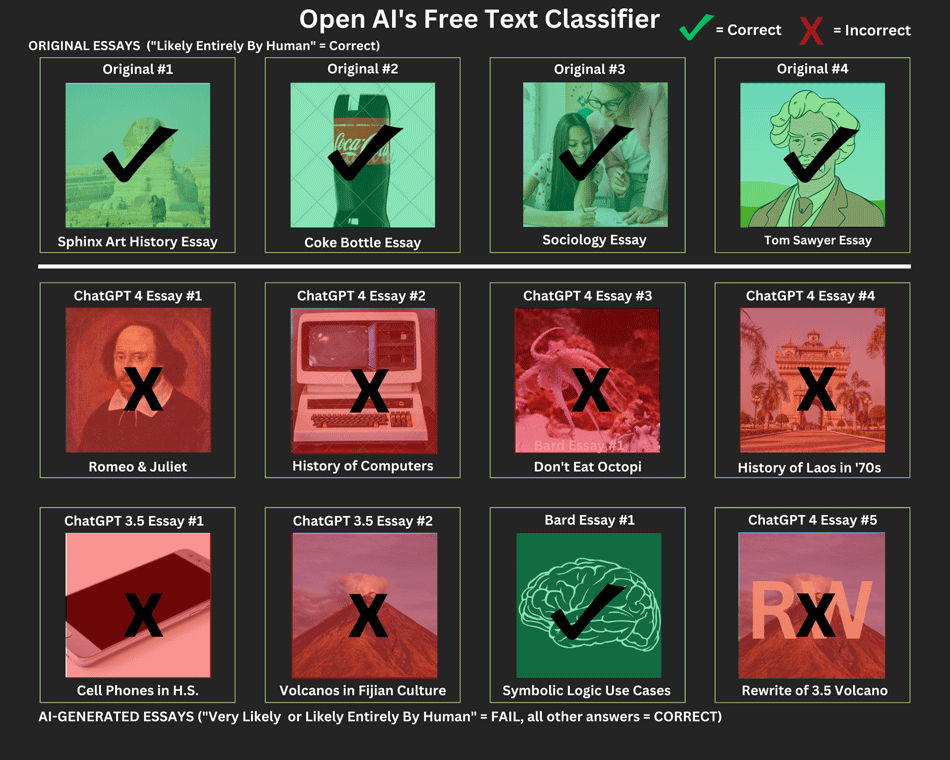
As you can see from the above, the system does fine on correctly classifying human-written content, but it also classified seven of the eight AI-generated essays as human-written (the only one it caught was the one written by its main competitor, Google Bard).
From the results, it seems like this tool isn't really tuned to detect current GPT 3.5 or 4 output. Perhaps if we wrote some essays using ChatGPT 3, it would have detected them, but as no one is really using that model right now, we did not take the time to test that.
Note that OpenAI itself said in the launch announcement that the tool "is not fully reliable," correctly identifying AI text 26% of the time. It fared a little worse in our test but, again, this identifier came out before 3.4, so it may not have been updated for it.
(Many) Free Online AI Detectors
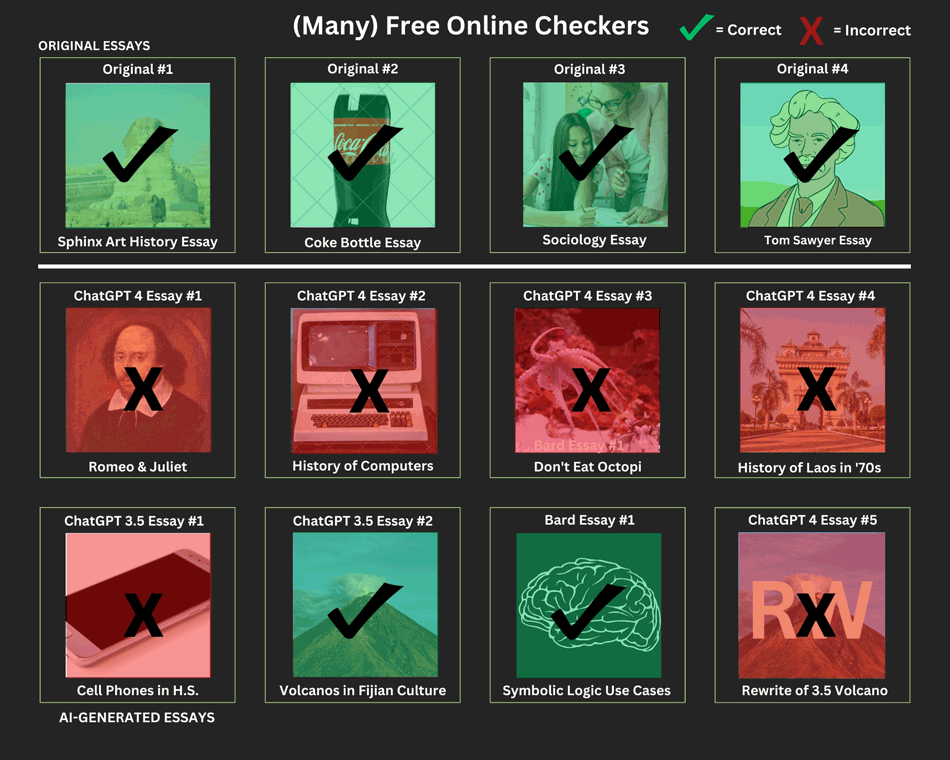
Next we tested an unnamed free online detector and got the below results. Then we tested another and got the exact same results (just with slightly different wording), and both were almost exactly the same as Open AI's Text Classifier above, except with one more AI-generated essay detected. We then tested two more; same exact results.
We had already suspected that many of these sites -- despite some saying that their detectors were "original" or "better" -- were using the same version of Open AI's detector (we suspect the API version may be slightly more accurate, thus the one more essay indicated), but since everything is just an educated guess, all we are going to say is that when looking for an AI detector online, it's possible that some of the free ones you run across will have output similar to the below:
Passed.AI
Passed.ai is a paid service that, similar to the first service we tested, gives a score with the likelihood of the content being output by AI. We decided to go with the same pass/fail criteria: If it determined that an original essay was more than 25% likely to be AI-written, that would be a fail, and an AI essay had to be at least 50% likely to be AI-written to pass. Here's how it did:
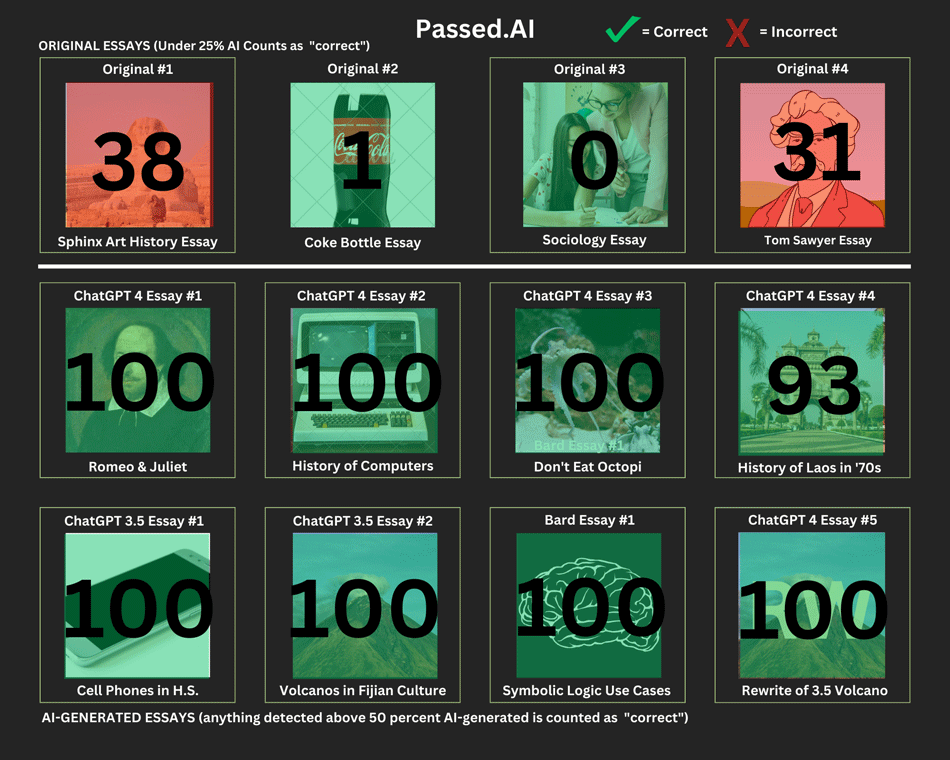
By our standards, it falsely flagged two of the original essays. However, it can easily be argued that our bar of more than 25% is the wrong standard of where a failure lies. It is the only system here that correctly identified 100% of the AI-generated content as AI-generated, and got the percentage of AI content very close, as well.
Results Summary
Below are all of the above results combined into one chart:
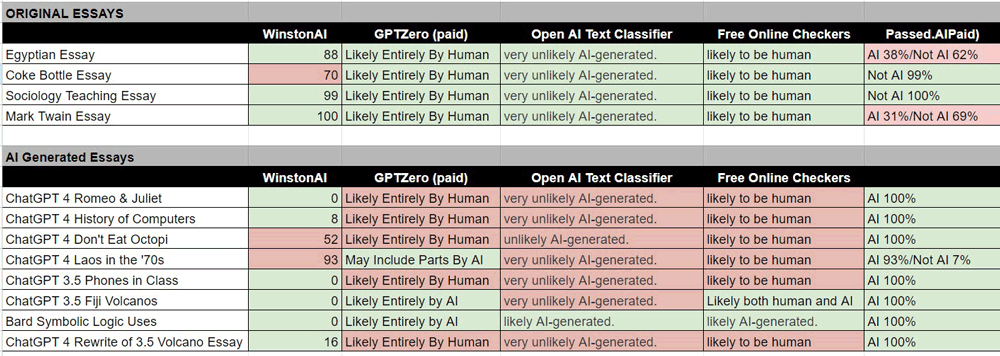
We'll leave the reader to draw whatever conclusions they'd like from these combined results. The bigger issue may be, does it matter? We'll leave you with some articles discussing the future of AI and, in particular, education (since this experiment involved essays):
For more AI content, go here and stay tuned to AI Test Lab for more forays into the possibilities and limits of generative AI.
About the Author
Becky Nagel serves as vice president of AI for 1105 Media specializing in developing media, events and training for companies around AI and generative AI technology. She also regularly writes and reports on AI news, and is the founding editor of PureAI.com. She's the author of "ChatGPT Prompt 101 Guide for Business Users" and other popular AI resources with a real-world business perspective. She regularly speaks, writes and develops content around AI, generative AI and other business tech. She has a background in Web technology and B2B enterprise technology journalism.