How-To
Researchers Demonstrate Transformer Architecture-Based Anomaly Detection for Cybersecurity
The new technique is based on deep neural transformer architecture (TA), originally intended for natural language processing but successfully adapted for other problem scenarios.
- By Pure AI Editors
- 08/02/2022
Researchers at Microsoft have demonstrated a new technique for anomaly detection. The technique is based on deep neural transformer architecture (TA). TA is an architecture that was originally intended for natural language processing. However, over the past two years, TA based systems have been successfully adapted for other problem scenarios.
Anomaly detection (AD) is a fundamental cybersecurity task. The goal is to identify unusual items in a dataset, such as a fraudulent credit card charge in a log file of transactions. There are dozens of techniques for anomaly detection. For example, one common approach, based on classical statistics, is to group the items in the dataset under investigation into k clusters using the k-means algorithm and then tag the data items that are furthest away from their cluster center.
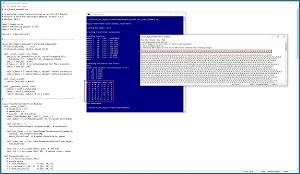 [Click on image for larger view.] Figure 1: Transformer Architecture Anomaly Detection in Action
[Click on image for larger view.] Figure 1: Transformer Architecture Anomaly Detection in Action
Figure 1 illustrates how the TA anomaly detection technique works. The system shown successfully identifies one anomalous item that had been placed into a dataset of 100 normal items. The data items are a subset of the UCI Digits dataset. Each item is a crude handwritten digit from "0" to "9."
The experiment created an anomalous item using a technique called the fast gradient sign method (FGSM) attack. The FGSM technique generates malicious data items that are designed to look normal to the human eye, but are misclassified by a trained neural network model.
Fast Gradient Sign Method (FGSM) in a Nutshell
In order to test an anomaly detection system, some anomalous data is needed. Figure 2 shows an example of a system that generates malicious data items using the FGSM attack technique. The source data is called the UCI Digits dataset. Each data item is an 8 by 8 image of a handwritten digit. Each of the 64 pixels is a grayscale value between 0 (white) and 16 (black). The UCI Digits dataset can be found at archive.ics.uci.edu/ml/machine-learning-databases/optdigits/. There are 3,823 training images and 1,797 test images.
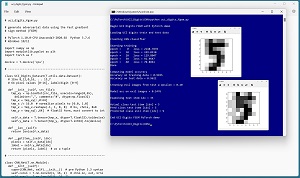 [Click on image for larger view.] Figure 2: Generating Malicious Data Using the FGSM Attack
[Click on image for larger view.] Figure 2: Generating Malicious Data Using the FGSM Attack
The UCI Digits dataset is derived from the well-known MNIST (Modified National Institute of Standards and Technology) dataset. MNIST images are handwritten digits from "0" to "9," but each image is 28 by 28 (784 pixels) and each pixel is a grayscale value from 0 to 255. The MNIST dataset has 60,000 training images and 10,000 test images. The UCI Digits dataset is often used instead of the MNIST dataset because the UCI Digits items are much easier to work with during early experimentation.
A neural network's weights determine the behavior of the network. The process of training a network/model is finding good values of the weights, in the sense that good weights give accurate predictions on a set of training data that has known correct labels/answers.
During training, the weights of a neural network model are updated using code that looks something like:
compute all weight gradients
for-each weight
new_wt = curr_wt - (learnRate * gradient)
end-for
Each neural weight is just a numeric value, typically between about -10.0 and +10.0. Each weight has an associated gradient, also just a numeric value. A gradient is just a numeric value that gives information about how (increase or decrease) to adjust the associated weight so that the model predictions are more accurate. The learnRate parameter is a value, typically about 0.01, that moderates the increase or decrease in the weight value.
For the FSGM attack, malicious data is generated using code that looks something like:
compute all input pixel gradients
for-each input pixel
bad_pixel = input_pixel + (epsilon * sign(gradient))
end-for
In training, weights are updated to increase network/model accuracy (technically, to reduce loss/error). In FGSM, input values are updated to decrease network/model accuracy. The epsilon parameter is a value, typically between 0.10 and 0.40, that moderates how different the malicious pixels are compared to the source good pixels.
Transformer Architecture in a Nutshell
The anomaly detection system created by the Microsoft researchers is based on transformer architecture. TA was originally developed in 2017 and was designed to handle long sequences of words, such as a paragraph of text. TA systems proved to be very successful and quickly replaced earlier systems based on LSTM architecture ("long, short-term memory"). Models based on LSTM architecture often work well for relatively short sequences (typically up to about 50-80 input tokens) but typically fail for longer sequences.
Models based on TA architecture are very complex, but neural code libraries such PyTorch have built-in Transformer modules that make working with TA models easier (but by no means simple). Predecessors to TA architecture models, such as LSTM models, read in and process input tokens one at a time. TA models accept an entire sequence at once and process the entire sequence. The result is a more accurate model at the expense of significantly increased complexity and slower performance.
Under the hood, a TA-based model converts an input sequence into an abstract numeric interpretation called a latent representation. The latent representation can be thought of as a condensed version of the input sequence that captures the complex relationships between the input tokens, including their order.
TA based models fall into two general categories: sequence-to-value, and sequence-to-sequence. Examples of sequence-to-value problems are predicting the next word in a sentence or predicting the sentiment (positive or negative) of a movie review. An example of a sequence-to-sequence problem is translating an English sentence to an equivalent German sentence.
How the Transformer Anomaly Detection System Works
The TA based anomaly detection system developed by Microsoft researchers is conceptually quite simple but the engineering details are tricky. The system scans each item in the source dataset and uses a Transformer component to generate a condensed latent representation of the item. Then, a standard deep neural network decodes the latent representations and expands each item back to a format that is the same as the source data.
For the demo shown in Figure 1, the source input of one data item is a vector of 64 pixel values. Each data item is converted to a latent representation, and the latent representation is expanded back to a vector of 64 values. At this point, each data item has an original value (in the case of UCI Digits, a vector of 64 values between 0 and 16), and a reconstructed value (also a vector of 64 values between 0 and 16). The anomaly detection system compares each item's original value with its reconstructed value. Data items with large reconstruction error don't fit the TA model and must be anomalous in some way.
What Does It Mean?
The Pure AI editors spoke to Dr. James McCaffrey from Microsoft Research, who noted, "We were somewhat surprised at how effective the transformer architecture anomaly detection system was on small dummy datasets. The TA system worked much better than other anomaly detection systems at detecting FGSM attack items."
Furthermore, McCaffrey added, "Most important datasets are not images such as the MNIST or UCI Digits datasets. Experiments with the transformer architecture anomaly detection system were effective for other types of data such as tabular data (the Boston Area Housing dataset), system log file data (Windows media log files), and natural language data (the IMDB Movie Review dataset).
"A disadvantage of the transformer-based system compared to classical anomaly detection techniques is that the TA system has many hyperparameters, such as the size of the latent representation, that must be tuned carefully to get good results."
The Microsoft Research data scientist concluded with a positive assessment: "There is no single best way to perform anomaly detection. And in most AD systems, it's important to have humans in the loop. That said, transformer architecture anomaly detection appears to be an important and practical new technique."