How-To
Researchers Generate Realistic Images from Text
- By Pure AI Editors
- 06/01/2022
Researchers at Google have demonstrated a new technique that generates photo-realistic images from arbitrary text. The technique is implemented in a system called Imagen ("image generation") that combines image diffusion generation with text transformer architecture language understanding. The Imagen system is described in a May 2022 research paper titled, "Photorealistic Text-to-Image Diffusion Models with Deep Language Understanding."
The idea is best explained by a few examples. Figure 1 shows three artificially generated images from text captions. The three captions are:
- "A transparent sculpture of a duck made out of glass. The sculpture is in front of a painting of a landscape."
- "A marble statue of a Koala DJ in front of a marble statue of a turntable. The Koala is wearing large marble headphones."
- "A giant cobra snake on a farm. The snake is made out of corn."
The generated images are not mere composites of existing images; the generated images are created from scratch, pixel by pixel. The results are quite remarkable.
 [Click on image for larger view.] Figure 1: Three examples of images created by the Imagen system. (source: Google).
[Click on image for larger view.] Figure 1: Three examples of images created by the Imagen system. (source: Google).
Image Generation Using Diffusion
There are several techniques to generate images. One of the first breakthrough techniques used was a deep neural variational autoencoder (VAE). VAEs were introduced in 2013. VAEs are relatively simple to implement, but in general the images produced by VAEs can be identified by humans as artificial.
A technique using deep neural generative adversarial network (GAN) was developed in 2014. GANs can produce very realistic images but implementing a GAN is extremely difficult.
A technique to create images called diffusion generation was proposed in 2015 and perfected in 2021. The images produced by a diffusion system are often state-of-art and cannot be distinguished from real photo images.
Diffusion works by taking a low-resolution image and builds a corresponding high-resolution image from pure noise. The model is trained on an image corruption process in which noise is progressively added to a high-resolution image until only pure noise remains. It then learns to reverse this process, beginning from pure noise and progressively removing noise to reach a target distribution through the guidance of the input low-resolution image. The idea is illustrated in Figure 2.
 [Click on image for larger view.] Figure 2: Image generation using diffusion. A low-resolution image source (left) is reduced to noise. The diffusion system learns to reconstruct the image from noise. The result is a high-quality reproduction (right). (source: Google).
[Click on image for larger view.] Figure 2: Image generation using diffusion. A low-resolution image source (left) is reduced to noise. The diffusion system learns to reconstruct the image from noise. The result is a high-quality reproduction (right). (source: Google).
Natural Language Understanding Using Transformer Architecture
The Imagen system accepts as input a text caption in free form natural language. The part of the system that interprets the text input uses transformer architecture (TA). TA systems were introduced in 2017 and have revolutionized natural language systems. TA systems are complex and huge, often with billions of numeric parameters. TA systems are typically trained on a massive dataset, for example, the entire text of all of Wikipedia. The diagram in Figure 3 is one example of a transformer architecture system with PyTorch library code snippets.
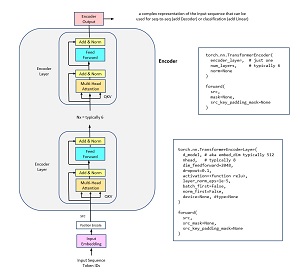 [Click on image for larger view.] Figure 3: Part of a Transformer Architecture System.
[Click on image for larger view.] Figure 3: Part of a Transformer Architecture System.
What Does It Mean?
Image generation systems like Imagen and inevitable successors raise interesting ethical questions because there are clearly ways that realistic fake images can be misused. And Imagen relies on TA text encoders trained on raw uncurated web-scale data, and so the system inherits the biases and limitations common to all large language models.
The Pure AI editors spoke to Dr. James McCaffrey from Microsoft Research. McCaffrey has extensive experience working with image generation systems and natural language systems. He commented, "The images produced by the Imagen system are very impressive, and in my opinion represent a significant step forward in image generation state of the art."
McCaffrey added, "I suspect that sophisticated text-to-image systems like Imagen may have several unexpected consequences. For example, there could be both positive and negative impacts on freelance artists and photographers."
McCaffrey also noted, "The ability to create fake images that can fool humans likely means it will become increasingly important to the develop machine learning security systems that can distinguish real images from fake images."