Machine Learning 101: Top Tips for Launching Your First AI Project
From picking the project to prepping the data, Jen Underwood offers her top tips for successfully getting a new machine learning project off the ground in your enterprise.
Just like with any new, expansive technology, it can be hard to know where to start. And there really are a lot of options for enterprises and developers when it comes to integrating artificial intelligence and machine learning.
We recently got a chance to talk about the best ways for developers to get started with machine learning with DataRobot Senior Director Jen Underwood, who will be giving a session aimed at helping developers get started with machine learning at Artificial Intelligence Live! 2019 in November (part of Live! 360). Here's what she shared with us:
One of the topics of your session, "Machine Learning 101 for Developers," is "selecting the right types of problems to solve." Can you elaborate a bit on this and what makes a problem "right" or wrong" for machine learning?
Don't get confused by machine learning hype. AI is not a magic wand that can solve any type of problem. Machine learning is a subset of artificial intelligence (AI) in which algorithms learn to predict outcomes and uncover patterns from historical data that are not easily spotted by humans. While most statistical analysis relies on rule-based decision-making, machine learning excels at tasks that are hard to define with exact step-by-step rules. If you have a simple rule-based problem, you don't need machine learning.
 "Don't get confused by machine learning hype. AI is not a magic wand that can solve any type of problem."
"Don't get confused by machine learning hype. AI is not a magic wand that can solve any type of problem."
Jen Underwood, AI and Analytics Expert
Within the field of machine learning, there are two main types of tasks: supervised, and unsupervised. Supervised machine learning algorithms uncover insights, patterns, and relationships from a labeled training dataset – that is, a dataset that already contains a known value for the target variable for each record. Because you provide the machine learning algorithm with the correct answers for a problem during training, it is able to "learn" how the rest of the features relate to the target, enabling you to uncover insights and make predictions about future outcomes based on historical data. Examples of Supervised Machine Learning Techniques include Regression and Classification. Regression returns a numerical target for each example, such as how much revenue will be generated from a new marketing campaign. Classification, in which the algorithm attempts to label each example by choosing between two or more different classes.
Unsupervised machine learning algorithms infer patterns from a dataset without reference to known, or labeled, outcomes. Unlike supervised machine learning, unsupervised machine learning methods cannot be directly applied to a regression or a classification problem because you have no idea what the values for the output data might be, making it impossible for you to train the algorithm the way you normally would. Unsupervised learning can instead be used for discovering the underlying structure of the data. The best time to use unsupervised machine learning is when you don't have data on desired outcomes. Some examples of unsupervised machine learning techniques include Clustering, Anomaly detection and Association. Clustering allows you to automatically split the dataset into groups according to similarity. Anomaly detection can automatically discover unusual data points in your dataset. This is useful in pinpointing fraudulent transactions, discovering faulty pieces of hardware, or identifying an outlier caused by a human error during data entry. Association identifies sets of items that frequently occur together in your dataset. Retailers often use it for basket analysis.
What are some of the top use cases you're currently seeing for developers getting started with machine learning?
One of my favorite overviews of AI uses cases by industry was created by McKinsey. You can explore the interactive chart by industry and problem type. The related Notes from the AI Frontier article is an excellent read for newcomers to AI. For developers, cloud cost estimation and churn detection are popular, practical AI use cases.
Why Python? What makes it work so well for AI/machine learning projects?
Python is currently ranked as the number one, most popular programming language in the world. For machine learning roles, Python programming is a must-have skill. Python is an open source language that is easy to learn, easy to use, and has over 140,000 powerful libraries for data analysis and data science. Machine learning libraries such as scikit-learn, Numpy, Scipy, Matplotlib, TensorFlow, Keras and NLTK are widely used in scientific computing and highly quantitative domains such as finance, oil and gas, and physics. Other reasons why Python is fantastic for AI/machine learning projects – it is a stable and flexible platform independent language that is supported by a large global community.
What is your No. 1 tip for preparing data for machine learning projects?
Beware of fundamental design differences between application, reporting and machine learning data model types.
Data preparation for machine learning is both an art and a science. You'll need to organize data for machine learning to accurately reflect a business process and outcome to evaluate. Since each data set, business objective and analysis are unique with varied data source challenges, there is no exact recipe for success. Depending on the project, data preparation might be a one-time activity or a periodic one. As new predictive insights get revealed, it is common to further experiment.
 source: Jen Underwood
source: Jen Underwood
Unlike other analytical techniques, machine learning algorithms rely on carefully curated data sources. You'll need to organize your data into one "flattened" analytical table of variables. Columns in machine learning datasets are referred to as features. Features and feature engineering are the creative part of machine learning that requires knowledge of the data and the business. Feature engineering improves model performance and accuracy. Some AutoML solutions do not perform automated feature engineering at all while others only automate basic feature creation. The best AutoML solutions in the market have deep feature engineering capabilities that you can visually explore and tune to generate high quality models.
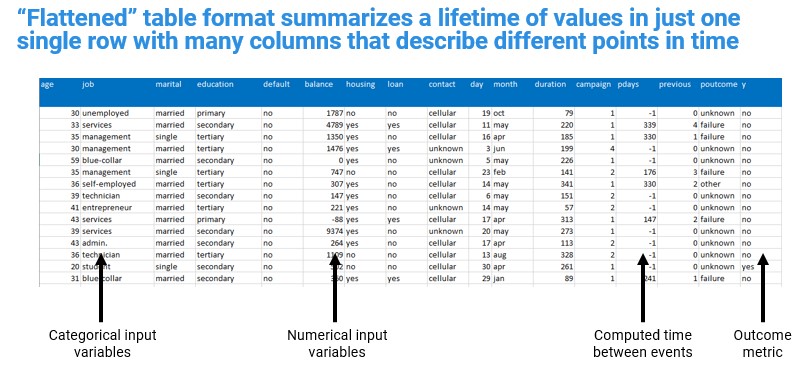 source: Jen Underwood
source: Jen Underwood
For more information, please read through my previously written articles on this vital topic.
What is the No.1 worst thing that programmers new to machine learning can do when starting a new project?
The most common mistake I see from programmers is underestimating the crucial importance of preparing data properly for machine learning. If you just point machine learning tools or scripts at relational databases, you will build bad models…and might not even know it. Don't get lazy and skip data prep. You will regret it.
About the Author
Becky Nagel serves as vice president of AI for 1105 Media specializing in developing media, events and training for companies around AI and generative AI technology. She also regularly writes and reports on AI news, and is the founding editor of PureAI.com. She's the author of "ChatGPT Prompt 101 Guide for Business Users" and other popular AI resources with a real-world business perspective. She regularly speaks, writes and develops content around AI, generative AI and other business tech. She has a background in Web technology and B2B enterprise technology journalism.