In-Depth
RAG (Retrieval-Augmented Generation) for Not-Quite-Dummies
- By Pure AI Editors
- 10/01/2025
RAG (retrieval-augmented generation) is a fundamental and essential part of modern AI. RAG allows large language models, such as GPT, to supplement their knowledge with custom information. There are dozens of explanations of RAG available on the Internet. But these explanations tend to be either too technical (for an engineering audience) or too fluffy (for an audience without any technical background whatsoever). This short article splits the difference in explanation approaches using a diagram and a concrete code example.
Large language models (GPT from OpenAI, Llama from Meta, Gemini from Google, and so on) are pretty amazing. Because the models have been trained using sources including Wikipedia, the models understand English grammar and know lots of facts. But if you want to query proprietary data sources, such as a company handbook, you need to supply the LLM with that proprietary data.
How RAG Systems Work
All of the LLMs can do RAG in roughly the same way, but the details differ. The diagram in Figure 1 illustrates a generic RAG system. A vector store holds a vector database (the two terms are often used interchangeably). Unlike a standard SQL database which stores text information in a highly structured way, a vector database stores unstructured documents in a special numeric format called word embeddings. You can think of word embeddings as the native language of an LLM. Different LLMs use different embeddings.
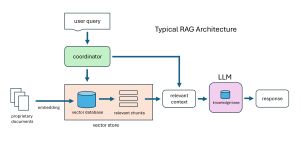 [Click on image for larger view.] Figure 1: Generic RAG System
[Click on image for larger view.] Figure 1: Generic RAG System
Proprietary documents are uploaded into a vector database. When a user queries the LLM+RAG system, the query first goes to the vector store, and relevant information related to the query is extracted. Behind the scenes, the vector store looks at chunks of embedded information, speeding up the process. The relevant information from the vector store is combined with the user query and sent to the LLM. The LLM uses its knowledge of grammar and its own knowledge base to generate a response.
A usual question is, "Why use a complicated vector store instead of just using a SQL database?" In fact, early pre-RAG systems did exactly that. Because a vector store holds pre-computed word embeddings, and because a vector store is intelligent enough to search just relevant chunks instead of its entire database, using a vector store is usually faster and is usually more accurate than using a SQL database architecture.
A Concrete Example of RAG
Here's a simple concrete example of RAG using the OpenAI API with the GPT large language model. The details are specific to GPT but all LLMs work essentially in the same way. The output of the demo program is shown in Figure 2.
The demo starts with a proprietary text file with fake information about the planet Mercury:
Mercury is the closest planet to the sun. A little-known
fact is that the surface of Mercury is purple. Mercury
is sometimes called the "grape planet".
The demo asks about the diameter and nickname of Mercury. The output of the simple RAG demo is:
Begin simple RAG demo
Creating demo vector store
Done. Store ID = vs_68d6a1xxxxxxxxxxxxxxxxxxbe26d92a
Uploading a text file to vector store
The query is:
What is the diameter and nickname of the planet Mercury?
The response is:
The nickname of Mercury is the "grape planet." However,
the diameter of Mercury is not provided in the file you
uploaded. If you need the diameter, the generally accepted
value is about 4,880 kilometers. The nickname, according
to your file, is "grape planet" due to its purple surface.
Deleting demo vector store
End RAG demo
The demo creates a vector store. Recall that a vector store has a database (like SQL) but the information is stored as numeric "embedding vectors" instead of text.
After the bogus text file about Mercury is uploaded to the vector store, the demo program asks, "What is the diameter and nickname of the planet Mercury?" The GPT LLM knows about the diameter of Mercury from its base knowledge, and the LLM knows about the bogus nickname from the file in the vector store.
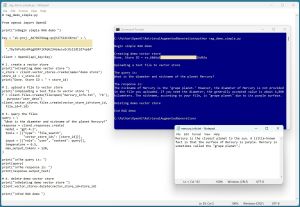 [Click on image for larger view.] Figure 2: A Simple Example of RAG in Action
[Click on image for larger view.] Figure 2: A Simple Example of RAG in Action
The demo concludes by deleting the vector store so that the user isn't charged for long-term storage.
Instead of using RAG with a vector store, a more primitive way to augment a LLM with proprietary information is simply to feed that information directly to the LLM in text form as part of the context, along with the query. But RAG can handle very large files that might not fit into a query context, and RAG can easily deal with lots of files.
For the Technically Inclined
Even if you don't know much or anything about computer coding, you should be able to understand most of the underlying program code.
Here is the Python language source code for the demo program. It has no error checking to keep ideas as clear as possible.
# rag_demo_simple.py
from openai import OpenAI
print("Begin simple RAG demo ")
key = "xxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxx"
client = OpenAI(api_key=key)
# 1. create a vector store
print("Creating demo vector store ")
v_store = client.vector_stores.create(name="demo store")
store_id = v_store.id
print("Done. Store ID = " + store_id)
# 2. upload a file to vector store
print("Uploading a text file to vector store ")
f = client.files.create(file=open("mercury_info.txt", 'rb'),
purpose="user_data")
client.vector_stores.files.create(vector_store_id=store_id,
file_id=f.id)
# 3. query the files
query = \
"What is the diameter and nickname of the planet Mercury?"
response = client.responses.create(
model = "gpt-4.1",
tools = [{"type": "file_search",
"vector_store_ids": [store_id]}],
input = [{"role": "user", "content": query}],
temperature = 0.5,
max_output_tokens = 120,
)
print("The query is: ")
print(query)
print("The response is: ")
print(response.output_text)
# 4. delete demo vector store
print("Deleting demo vector store ")
client.vector_stores.delete(vector_store_id=store_id)
print("End RAG demo ")
Wrapping Up
Even a quick glance at the demo program indicates how relatively easy it is to implement a RAG system. The Pure AI editors asked Dr. James McCaffrey to comment. McCaffrey was one of the original members of the Microsoft Research Deep Learning group.
McCaffrey observed, "The latest versions of APIs for GPT, Llama, Gemini, and other LLMs make it much easier to implement a RAG system than it used to be. As recently as just a few months ago, deploying a RAG system was much more difficult because the vector database and various connectivity components had to be implemented separately. But now APIs integrate RAG functionality into small, easy-to-use modules."
He added, "One possible downside to RAG systems such as the one described in this article is security. However, companies that offer LLM services are well aware of security issues and there are ways to deal with most scenarios."