How-To
Understanding LLM Distillation, Enabling Revolutionary DeepSeek R1 Model
For the techies, here's an explanation of one of the key factors behind the new breakthrough model that exhibits top-notch performance on the cheap.
- By Pure AI Editors
- 02/03/2025
The release of the R1 large language model (LLM) from Chinese company DeepSeek last month stunned the AI technical community and rocked the stock price of several huge tech companies.
Compared with competitors like the OpenAI o1 model, R1 performed as well or better on most benchmark AI tasks, R1 was approximately 30 times less expensive to create than o1 (estimated at $6 million vs. $500 million, although exact costs are not known outside of each company), and R1 is approximately 25 times less expensive to use than o1 (roughly $2.19 per million tokens vs. $60 per million tokens, depending on usage scenario).
Preliminary analyses of R1 suggest that three key factors that contribute to its performance and low costs are:
- Chain-of-thought reasoning (explicitly using intermediate steps in the logic process)
- Reinforcement learning augmented training (training using reward feedback rather than the known correct outputs from Wikipedia text)
- Model distillation
Model Distillation
Large language model distillation is the process of reducing the size of a model to a smaller version that has approximately the same accuracy as the larger model. The smaller model will have less storage requirements and have faster response times than the original larger model, and therefore be much less expensive to operate and to use during inference time.
Most information about LLM distillation tends to be either extremely technical -- a research paper sprinkled generously with math equations filled with Greek letters, or be extremely non-technical -- not enough information to help you really understand what distillation is and how to use that information to make business decisions. This article aims to describe LLM distillation at an in-between level by showing you a concrete example.
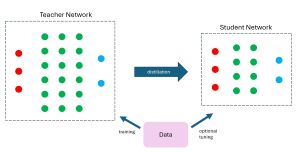 [Click on image for larger view.] Figure 1: The Teacher-Student Technique for Model Distillation
[Click on image for larger view.] Figure 1: The Teacher-Student Technique for Model Distillation
There are several ways to perform model distillation. One of the most common is called the teacher-student technique. In a nutshell, the teacher model is large, and is trained using standard training data with known, correct target values. The student model is trained by using the predictions of the teacher model instead of using training data. Put another way, the student model learns to mimic the teacher model. The diagram in Figure 1 illustrates the teacher-student technique for model distillation.
There are many variations of the teacher-student technique. The diagram in Figure 1 assumes that the data used to train the large teacher model is also available to train and fine-tune the student model. However, this is not a requirement. It is possible to create a small teacher model without access to the source training data. In other words, it is feasible for any person or company with sufficient computing resources to mimic an existing LLM.
Example Data
The demo model distillation program uses a set of synthetic data that looks like:
1, 0.24, 1, 0, 0, 0.29500, 2
-1, 0.39, 0, 0, 1, 0.51200, 1
1, 0.63, 0, 1, 0, 0.75800, 0
. . .
Each line of data represents a person. The fields are sex (male = -1, female = +1), age (divided by 100), state of residence (Michigan = 100, Nebraska = 010, Oklahoma = 001), income (divided by $100,000), and political leaning (conservative = 0, moderate = 1, liberal = 2). The goal is to predict a person’s political leaning from sex, age, state, and income. There are just 200 training items and 40 test items.
Of course, in a large language model scenario, the training data is a huge collection of text data, such as the entire contents of Wikipedia, plus non-copyrighted books, news articles, and so on. For an LLM, the goal is to predict the next word, given a context prompt such as, "The quick brown ******."
Example Distillation
The demo distillation program uses the PyTorch code library, which is the de facto standard for nearly all modern AI systems. The screenshot shown in Figure 2 has three main sections. The first part of the demo output is:
Creating 6-(100-100)-3 teacher network
Training teacher network
bat_size = 10
loss = NLLLoss
optimizer = SGD
max_epochs = 2000
lrn_rate = 0.005
epoch = 0 loss = 21.4943
. . .
epoch = 1500 loss = 9.6615
Teacher accuracy on training data = 0.8350
Teacher accuracy on test data = 0.6750
Predict politics for M, 36, Michigan, $44,500
tensor([[0.0855, 0.8515, 0.0629]])
1
The 6-(100-100)-3 teacher neural network has 6 input nodes, two hidden layers each with 100 nodes, and 3 output nodes. The teacher model has (6 * 100) + (100 * 100) + (100 * 3) + 100 + 100 + 3 = 11,103 weights and biases. (In an LLM, weights and biases are often called trainable parameters.) The teacher scores 83.50% accuracy on the training data (167 out of 200 correct) and 67.50% accuracy on the test data (27 out of 40 correct).
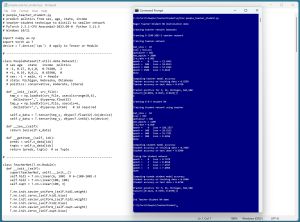 [Click on image for larger view.] Figure 2: Demo Distillation Program in Action
[Click on image for larger view.] Figure 2: Demo Distillation Program in Action
The teacher model predicts that a person who is (M, 36, Michigan, $44,500) has political leaning 1 (moderate) with a pseudo-probability of 0.8515. The output is in the form of pseudo-probabilities that sum to 1 and indicate the likelihood of conservative, moderate, and liberal respectively. In a large language model scenario, the output is a very large vector (perhaps 10,000 or more values) where each value is the pseudo-probability of the next word/token.
The second part of the demo output uses the teacher model to create a small 6-8-3 student neural network:
Creating 6-8-3 student NN
Training student network using teacher
bat_size = 10
loss = MSE
optimizer = SGD
max_epochs = 1200
lrn_rate = 0.010
epoch = 0 loss = 186.2557
. . .
epoch = 900 loss = 8.4816
Student accuracy on training data = 0.7850
Student accuracy on test data = 0.6500
The 6-8-3 student neural network has just (6 * 8) + (8 * 3) + 8 + 3 = 83 weights and biases, which is less than 10% of the size of the large teacher network. The student network scores well (78.50% and 65.00% accuracy on train and test data).
The third part of the demo fine-tunes the student network. The training data is fed to the student network and data items that are incorrectly predicted (21.50% of 200 items = 43 items) are saved in a mistakes.txt file, and then that data is used to tune the student network:
Tuning the student network
epoch = 0 loss = 8.7479
. . .
epoch = 6 loss = 7.4056
Student accuracy on training data = 0.8500
Student accuracy on test data = 0.6750
Predict politics for M, 36, Michigan, $44,500
tensor([[0.1421, 0.7870, 0.0709]])
1
The tuned student neural network scores better than the teacher network on the training data (85.00% vs. 83.50% accuracy) and scores the same as the teacher network on the test data (67.50% accuracy).
So What's the Point?
Large language models can have billions of trainable parameters and so reducing their size can save many millions of dollars. Most companies do not have the resources needed to create their own distilled LLM model, but many companies will find it beneficial to use a distilled model from service providers such Microsoft, Google, Amazon, and OpenAI. This article demonstrates that model distillation is relatively simple (at least conceptually) and the key question to ask is, "How easy is it to customize the distilled model to meet my business scenario?"
Dr. James McCaffrey, from Microsoft Research, commented, "Some of my research colleagues speculate that the appearance of the DeepSeek R1 model suggests that large language models may eventually become commodities."
McCaffrey added, "Business opportunities might arise where the goal is not to create distilled LLMs, but instead, create systems and agents that use distilled LLMs. An analogy is that during the introduction of electricity in the late 1800s, electricity-producing companies created wealth, but far greater wealth was generated by companies that invented devices that use electricity.
"Some of my non-research colleagues have mentioned that LLM distillation raises interesting legal questions. For example, suppose some AI startup company takes an existing LLM and uses it to create a distilled model. Who owns the intellectual property rights to the distilled model? These are questions outside of our area of expertise but are ones that will likely have a big impact on the evolution of AI systems."