News
Microsoft Stirs Interest with Small, Fine-Tuned Orca-2 LLM
- By Pure AI Editors
- 12/01/2023
Although the GPT-x large language models from OpenAI are the best known LLMs, other companies are moving forward with their own LLMs. Last month, Microsoft announced the availability of the Orca-2 LLM. See the blog post, "Orca 2: Teaching Small Language Models How to Reason."
According to the Pure AI technical experts, Orca-2 is a significant development. The three key takeaways are:
- It is possible to create relatively small, fine-tuned LLMs from a large LLM, without losing effectiveness.
- The effectiveness of a LLM depends about equally on the size of the model and the quality of the data used to train the model.
- It is possible to use synthetic training data that has been generated from other LLMs.
What is Orca-2?
Orca-2 is explained in a rather lengthy 53-page research paper. Briefly, Orca-2 is a fine-tuned version of the LLaMA-2 LLM. LLaMA-2 (Large Language Model Meta AI) is a family of models from the AI group at Meta, the parent company of Facebook. LLaMA-2 models range in size from 7 billion to 70 billion parameters. LLaMA-2 was released in mid-July 2023.
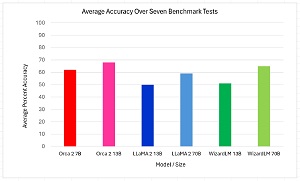 [Click on image for larger view.] Figure 1: The Relatively Small Orca-2 Model Performs Comparably with Larger Models
[Click on image for larger view.] Figure 1: The Relatively Small Orca-2 Model Performs Comparably with Larger Models
There are currently two versions of Orca-2, one with 7 billion parameters and one with 13 billion parameters. Rather than being fine-tuned by using only existing human-generated data sources, Orca-2 was trained in part by using synthetic training data that was generated by conversations with the GPT-4 model. Other techniques to generate synthetic training data, such as inverting content from the FLAN (Fine-tuned LAnguage Net) dataset from Google, were also used to train Orca-2.
The graph in Figure 1 shows that the relatively small Orca-2 7B and 13B models perform comparably to the significantly larger 13B and 70B LLaMA-2 and WizardLM models. WizardLM is based on LLaMA-2 and is trained using a method called Evol-Instruct on complex instruction data. WizardLM was developed by Microsoft Research.
An Example of Orca-2
The Orca-2 research paper presents many examples. A typical example is the following problem:
John and Mark are in a room with a ball, a basket and a box. John puts the ball in the box, then leaves for work. While John is away, Mark puts the ball in the basket, and then leaves for school. They both come back together later in the day, and they do not know what happened in the room after each of them left the room. Where do they think the ball is?
This is a fairly simple reasoning problem for an adult human but is very difficult for a computer system. The Orca-2 13B model responds correctly with:
Let's analyze the situation step by step:
1. John puts the ball in the box.
2. John leaves for work.
3. Mark comes into the room and puts the ball in the basket.
4. Mark leaves for school.
5. John and Mark both return to the room.
At this point, John and Mark have not seen each other's actions. Therefore, they only know what happened while they were in the room. John only saw the ball in the box before he left for work. Mark only saw the ball in the basket before he left for school. Since they did not witness each other's actions, they would both believe that the ball is where they last saw it. So, John would think the ball is in the box, and Mark would think the ball is in the basket.
The image in Figure 2 shows this example in the LM Studio tool. LM Studio can load LLMS, including Orca-2, stored on a local machine and exercise them. LM Studio is useful for comparing different LLMs.
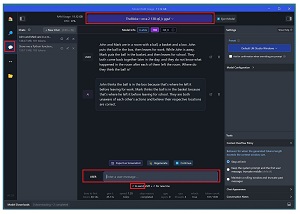 [Click on image for larger view.] Figure 2: Orca-2 in Action Via the LM Studio Tool
[Click on image for larger view.] Figure 2: Orca-2 in Action Via the LM Studio Tool
The Experts Comment
he Pure AI editors spoke to Dr. Hamid Palangi and Dr. James McCaffrey, both from Microsoft Research. Palangi is a member of the Orca-2 team and co-author of the Orca-2 research paper. McCaffrey is a research engineer who has extensive experience with Transformer Architecture software, the main underlying component of LLMs.
Palangi observed that a surprisingly difficult task is evaluating the correctness of a LLM. "Think of scenarios were one LLM declines to answer vs. a second LLM that does, and the second LLM gives the right answer but generates wrong justification for it," he said. "Or an LLM that generates the right answer but in the wrong format."
McCaffrey commented: "I was particularly interested in the use of synthetic data generated by other LLMs to train the Orca-2 LLM. The amount of high-quality human-generated training data, such as the text of Wikipedia, is large but ultimately finite. Using LLMs to train other LLMs is a fascinating idea with big implications."