How-To
Researchers Suggest a 'Physics of AI' Approach to Study Deep Learning Systems Like ChatGPT and Copilot
The reality is that exactly how these fantastically complex AI systems work is not fully understood. This is not good.
- By Pure AI Editors
- 03/01/2023
AI assistant applications such as the ChatGPT general information chatbot and the GitHub Copilot computer programming aide have entered mainstream usage. The reality is that exactly how these fantastically complex AI systems work is not fully understood. This is not good.
Researchers at Microsoft have suggested that the study of deep learning models such as GPT-3 and its associated applications should use an approach they call "the physics of AI." The two key principles of the physics of AI paradigm are:
- Explore deep learning phenomena through relatively simple controlled experiments.
- Build theories based on simple math models that aren't necessarily fully rigorous.
So, the physics of AI means to use experimental techniques that physicists have used since the 18th century, rather than applying the core concepts of physics, such as gravity and electromagnetism.
The idea is that more progress in understanding AI systems will be made by looking at simple scenarios than by looking at complex scenarios. An analogy given by researcher Dr. Sebastien Bubeck is that you can't understand the molecular structure of water by looking at Niagara Falls -- you must perform small experiments such as those done by chemist Henry Cavendish, who discovered the composition of water in 1781.
The Mystery of AI Fine-Tuning
The process of creating an AI assistant is best explained by a concrete example. A Transformer architecture is a complex software module that accepts a sequence of symbols, often ordinary English words. Large language models, such as GPT-3 (generative pre-trained transformer version 3), and BERT (bidirectional encoder representations from Transformers), use Transformer modules and an enormous corpus of English text including Wikipedia, web pages and book texts, to learn how to predict the next word in a sequence. The GPT-3 model has 175 billion numeric weights that are just constants like -1.234 and 0.987. In ways that are not understood, GPT-3 in some sense understands the English language. But by themselves, large language models are not particularly useful.
 [Click on image for larger view.] Figure 1: Dr. Sebastien Bubeck explains the physics of AI at the 2023 Association for the Advancement of Artificial Intelligence conference.
[Click on image for larger view.] Figure 1: Dr. Sebastien Bubeck explains the physics of AI at the 2023 Association for the Advancement of Artificial Intelligence conference.
A large language model like GPT-3 can be used as the starting point for an application such as an AI chemistry assistant or an AI computer programming assistant. New data, specific to the problem domain, is used to train the existing GPT-3 model to provide new functionality. The GPT-3 model is said to be the pre-trained model, and the resulting AI assistant is said to be the fine-tuned model.
Fine-tuning a model is usually accomplished using a machine learning technique called few-shot training. Few-shot training requires much less labeled training data than normal deep learning training techniques.
How the large language model fine-tuning process works is not completely known. Using a complex system without understanding how it works is likely a recipe for bad things to happen.
Exploring AI Fine-Tuning
In order to study deep learning models, Dr. Bubeck and his colleagues have created a small, manageable, synthetic reasoning task, called Learning Equality and Group Operations. Suppose there are six people in a room and you tell a friend the following six facts:
Evan is the same sex as Bret.
Drew is the opposite sex of Finn.
Alex is the same sex as Drew.
Cris is male.
Bret is the opposite sex of Cris.
Finn is the same sex as Evan.
The goal is to figure out the sex/gender (male = -1 or female = +1) of each of the six people in the room. The problem is relatively easy for a human to solve but surprisingly difficult for a computer.
Expressed as a sequence of mathematical symbols, the input sentence is:
e = +b; d = -f; a = +d; c = 1; b = -c; f = +e.
There are six variables to determine. When trained from scratch using a standard Transformer architecture system, the system can eventually learn how to handle all six-variable sequences. But when the trained system is presented with input sequences that have more than six variables, the model does not perform well.
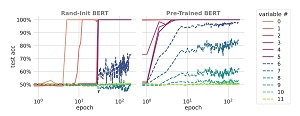 [Click on image for larger view.] Figure 2: The graphs illustrate that a reasoning system trained using fine-tuning can extrapolate from six variables to 12 variables.
[Click on image for larger view.] Figure 2: The graphs illustrate that a reasoning system trained using fine-tuning can extrapolate from six variables to 12 variables.
But instead of starting from scratch, if a reasoning system starts with a pre-trained BERT large language model, and then fine-tunes the system on the symbolic reasoning task, the resulting model can perform much better on longer sequences. Apparently, pre-trained large language model Transformer architecture networks learn general-purpose connections that allow a fine-tuned network to generalize better.
Dr. Bubeck and his colleagues performed a comprehensive set of experiments and believe they understand to a large extent how the fine-tuned system generalizes.
So, What Does It Mean?
The Pure AI editors spoke to Dr. James McCaffrey from Microsoft Research in Redmond, Wash. McCaffrey agrees with the physics of AI principle for exploring deep neural systems. "Transformer architecture AI systems are by far the most complex systems I've ever worked with," he said. "Understanding these systems cannot be accomplished by trying to analyze intractable systems like the GPT-3 based ChatGPT application."
McCaffrey added, "It's not clear to me, or to any of the colleagues I've spoken with, how quickly the field to understanding deep neural models will advance. But we all agree that it's crucial to understand how these increasingly common AI systems work."