How-To
Microsoft Researchers Use Neural Transformer Architecture for Cybersecurity
Transformer architecture (TA) is designed to handle long sequences of words, such as a paragraph of text.
- By Pure AI Editors
- 10/03/2022
Researchers at Microsoft have demonstrated two new systems that use deep neural transformer architecture for cybersecurity. The first system computes the similarity of two datasets. The second system identifies anomalous items in a dataset containing mixed numeric and non-numeric data.
Previous research has explored dataset similarity and anomaly detection using standard deep neural multi-layer perceptron architecture. The new systems use transformer architecture which is a significantly more sophisticated approach. A loose analogy is old electronics vacuum tube technology versus transistor technology. Both can be used to build a radio, but transistor technology is more powerful.
What Is Transformer Architecture?
Transformer architecture (TA) was introduced in 2017 and is designed to handle long sequences of words, such as a paragraph of text. TA systems proved to be very successful and quickly replaced earlier systems based on architectures such as LSTM ("long, short-term memory") and GRU ("gated recurrent unit"). Models based on LSTM and GRU architecture often work well for relatively short sequences (typically up to about 50-80 input tokens) but often fail for longer sequences.
Models based on TA architecture are complicated, but neural code libraries such PyTorch have built-in Transformer modules that make working with TA models easier. But even so, creating TA models is difficult and time-consuming.
Predecessors to TA architecture models read in and process input tokens one at a time. TA models accept an entire sequence at once and process the entire sequence. The result is a more accurate prediction model at the expense of increased complexity and slower performance.
Under the hood, a model based on TA converts an input sequence into an abstract numeric interpretation called a latent representation. The conversion component is often called a TransformerEncoder. The latent representation can be thought of as a condensed version of the input sequence that captures the relationship between the input tokens, including their order.
Models based on TA fall into two general categories: sequence-to-value and sequence-to-sequence. Examples of sequence-to-value problems are predicting the next word in a sentence, or predicting the sentiment (positive or negative) of an online restaurant review. An example of a sequence-to-sequence problem is translating an English sentence to an equivalent Italian sentence. Sequence-to-value systems use a TransformerEncoder module. Sequence-to-sequence systems use a TransformerEncoder module and a TransformerDecoder module.
Transformer-Based Dataset Similarity
A similarity metric between a dataset P and a dataset Q is a value that describes how similar (or nearly equivalently, how different) the two datasets are. At first thought, dataset similarity doesn't seem particularly useful or difficult. However, dataset similarity is a useful metric but very difficult to calculate.
Knowing the similarity between two datasets can be useful in several cybersecurity scenarios. One example is comparing two machine learning training datasets to determine if one has been compromised by a so-called poisoning attack. Another example is comparing two output datasets to determine if a prediction model has been compromised in some way.
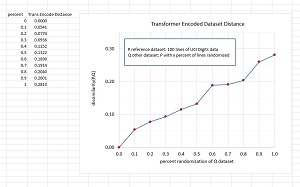 [Click on image for larger view.] Figure 1: Results of a Transformer-Based Dataset Similarity Experiment
[Click on image for larger view.] Figure 1: Results of a Transformer-Based Dataset Similarity Experiment
The terms dissimilarity (and similarity), distance and divergence are closely related. In informal usage, the terms are sometimes used interchangeably even though technically the terms represent different metrics.
There are many simple ways to compute the similarity between two individual numeric data items. Examples include Euclidean distance and cosine similarity. But calculating a similarity metric between two collections of data items is difficult for at least three reasons. First, brute force approaches that compare individual data items don't work for large datasets. Second, there's no effective way to deal with datasets that contain both numeric and non-numeric data. And third, there's no immediately obvious way to handle two datasets that have different sizes.
The new dataset similarity system demonstrated by researchers uses transformer architecture to encode the items in the P reference dataset. This produces a frequency distribution. The items in the Q "other" dataset are encoded which produces a second frequency distribution. The two distributions are compared using a classical statistics technique called Jensen-Shannon divergence.
The graph in Figure 1 shows the results of one experiment. As the difference between a reference P dataset and various Q "other" datasets increases, the value of the TA based dataset dissimilarity metric increases. Note that when P and Q are the same, the dissimilarity value is 0 as expected.
Transformer-Based Anomaly Detection
The new anomaly detection system based on TA developed by Microsoft researchers is conceptually simple, but the details are somewhat tricky. The system scans each item in the source dataset and uses a TransformerEncoder component to generate a condensed latent representation of each item. Then, a standard deep neural network decodes the latent representations and expands each item back to a format that is the same as the source data.
 [Click on image for larger view.] Figure 2: Results of a Transformer-Based Anomaly Detection Experiment
[Click on image for larger view.] Figure 2: Results of a Transformer-Based Anomaly Detection Experiment
For the demo shown in
Figure 2, the source input is a vector of values that represent a person. The data looks like:
1 0.24 1 0 0 0.2950 0 0 1
-1 0.39 0 0 1 0.5120 0 1 0
1 0.63 0 1 0 0.7580 1 0 0
-1 0.36 1 0 0 0.4450 0 1 0
. . .
The nine fields are sex (male = -1, female = +1), age (divided by 100), state (Michigan = 100, Nebraska = 010, Oklahoma = 001), annual income (divided by 100,000), and political leaning (conservative = 100, moderate = 010, liberal = 001). The data is synthetic and was programmatically generated.
Each data item is converted to a latent representation, and the latent representation is expanded back to a vector of nine values. At this point, each data item has an original value and a reconstructed value. The anomaly detection system compares each item's original value with its reconstructed value. Data items with large reconstruction error don't fit the TA model and must be anomalous in some way.
Previous research demonstrated anomaly detection based on TA for datasets where the data consists of all integers, such as image data and text converted to integer tokens. The new experiments demonstrated by researchers adapt TA to arbitrary data types using a technique called pseudo-embedding.
Because the data was programmatically generated, it was possible to generate anomalous data items. For example, certain combinations of sex, age, state and political leaning are correlated with a specific income range. Changing the income value of such data produces an anomalous item. The anomaly detection system based on TA successfully identified each anomalous item.
What Does It Mean?
The Pure AI editors spoke with Dr. James McCaffrey from Microsoft Research. McCaffrey commented, "Even though transformer architecture was originally designed for use with natural language processing problems, it has been successfully applied to a wide range of problem scenarios."
McCaffrey added, "It's somewhat surprising that transformer-based systems often perform better than standard neural-based systems, even when there is no explicit sequential data. We don't completely understand exactly why transformer systems work so well, and this is an active area of research."
McCaffrey further observed, "There is no single silver bullet technique for cybersecurity. Systems based on transformer architecture appear to be a promising new class of techniques." But he cautioned, "Because transformer architecture is so complex, it's important to do a cost-benefit analysis before starting up a TA project."