How-To
Contrastive Loss Representation for Anomaly Detection Has Cybersecurity Implications
- By Pure AI Editors
- 05/03/2022
Researchers have demonstrated that a machine learning technique designed for image recognition can be successfully applied to find anomalous items in a set of non-image data. That success has implications for improved cybersecurity techniques.
Briefly, a technique called contrastive loss representation for image data accepts an image (such as a 32 x 32 color image of a dog) and generates a numeric vector that is an abstract representation of the image (such as a numeric array of 500 values). The abstract representation vector can be used for so-called "downstream" tasks such as creating an image classifier, with only a very small number of images that are labeled with the correct class.
Contrastive loss representation was designed for use with image data. However, researchers have adapted the technique to work with non-image data such as log files. The abstract representations can be used to create an anomaly detection system that scans log files for items where the abstract representation vector is mathematically different (such as Euclidean distance) from an expected representation.
The Motivation
The ideas of contrastive loss representation for image data are perhaps best explained by using a concrete example. The CIFAR-10 (Canadian Institute for Advanced Research, 10 classes) dataset has 50,000 training images and 10,000 test images. Each image is 32 x 32 pixels. Because the images are color, each image has three channels (red, green, blue). Each pixel-channel value is an integer between 0 and 255. Each image is one of 10 classes: plane (class 0), car, bird, cat, deer, dog, frog, horse, ship, truck (class 9). Using all 50,000 training images it's relatively easy to create an image classification system that achieves about 90 percent accuracy.
Suppose you want to create an image classifier for a new dataset of 32 x 32 images where each image is one of three classes: bicycle, cow and rabbit. You only have 100 labeled training images for each class. If you create an image classifier from scratch using the 300 training images, your classifier will certainly have poor accuracy because you just don't have enough training data.
However, your (bicycle, cow, rabbit) image data is similar in some intuitive sense to the CIFAR-10 image data. If you could construct an internal representation of the CIFAR-10 data, there's a good chance you could use that representation to jump-start an image classifier for your data and get good accuracy even though you have a very limited amount of training data.
Understanding Contrastive Loss Representation for Image Data
Standard techniques for generating an abstract representation, such as using a deep neural autoencoder, work quite well for some purposes but have a weakness that there is no logical-mathematical relationship between the representations of similar classes. For example, you'd expect abstract representations of dog and cat images to be more mathematically similar than abstract representations of dog and ship images.
Systems called variational autoencoders produce internal representations that have some relationship between classes, but the abstract representations created by variational autoencoders do not, in general, work well to jump-start downstream tasks. This drawback motivated the creation of contrastive loss systems.
The term "contrastive loss" is general, meaning there are several different types of contrastive loss functions, and several different neural architectures that use contrastive loss. Briefly, a contrastive loss function accepts two data items (usually images) and returns a small value if the two data items are similar and a large value if the items are dissimilar.
One of the most common contrastive loss systems is called SimCLR (simple contrastive loss representation). SimCLR uses a contrastive loss function called NT-Xent (normalized temperature-scaled cross entropy loss). The SimCLR system was first described in a 2020 research paper "A Simple Framework for Contrastive Learning of Visual Representations" by T. Chen, S. Kornblith, M. Norouzi and G. Hinton. The paper can be found in PDF format using an internet search.
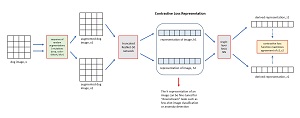 [Click on image for larger view.] Figure 1: Contrastive Loss Representation for Image Data
[Click on image for larger view.] Figure 1: Contrastive Loss Representation for Image Data
The diagram in Figure 1 shows most of the key ideas of SimCLR for image data. The input is a 32 x 32 CIFAR-10 color image. The image is sent twice to a sequence of three augmentations:
- A random part of the image (such as a 9 x 9 block of pixels) is cropped and then resized back to 32 x 32 pixels.
- The colors are randomly distorted.
- Gaussian blur is applied.
The result is a pair of augmented images, x1 and x2. Note that "augmented" usually means "added to" but in the context of contrastive loss, "augmented" means "mutated."
The pair of augmented images (x1, x2) are fed to a ResNet-50 neural network. ResNet-50 is a large neural network with 50 layers used for image classification. Intermediate results of the ResNet-50 network (h1, h2), just after the average pooling layer, are fetched rather than the final output vector of 10 values. The (h1, h2) outputs from the ResNet-50 component are abstract representations of the two augmented images. These two abstract representations could be compared by a contrastive loss function. But it was discovered that passing the representations to a simple, single-hidden-layer neural network to get a pair derived representations (z1, z2) and then feeding the derived representations to the normalized temperature-scaled cross entropy contrastive loss function works better.
The results of the loss function are used to update all the weights and biases in the SimCLR system. This results in the internal h1 and h2 representations being better. After training, the internal h-representations can be used for downstream tasks.
One thing that the diagram leaves out is that a SimCLR network is trained using a batch of pairs of images. The first pair are similar to each other as shown, but the other pairs are randomly selected and are assumed to be dissimilar. The similar and dissimilar pairs are actually fed to the contrastive loss function, not just the similar pair as shown.
Applying Contrastive Loss to Non-Image Data
Researchers at Microsoft in Redmond, Wash., explored the idea of using a contrastive loss system applied to non-image data, such as log files. A key advantage of contrastive loss systems is that they don't require labeled data to identify pairs of similar items. Instead, pairs of similar items are generated by augmenting/mutating a data item. Dissimilar items can be generated by augmenting/mutating any other randomly selected data item, even though there's a small chance the second data item could have the same class label as the first item. Generating virtual training labels in this way is called self-supervised learning (as opposed to supervised learning where class labels must be explicitly supplied). The Microsoft researchers realized that a self-supervised technique is necessary for log file data, which often have millions of items.
Augmenting non-image data has fewer options than augmenting image data. The Microsoft researchers augmented normalized numeric data by adding or subtracting a percentage that was a learned parameter -- determined during training. Typically, adjusting numeric data by a factor of 0.05 worked well. Non-numeric log data was first converted to a numeric form using one-hot encoding, and then augmented. Typically, the adjustment factor for encoded data was roughly one-tenth of that used for standard numeric data.
After creating a contrastive loss system for log file data, the internal representation was used to fine-tune an anomaly detection system. In preliminary, unpublished results, the contrastive loss anomaly detection system had an accuracy of 86 percent on a set of synthetic data, which is somewhat better than the 82 percent accuracy achieved by other neural architectures.
What Does It All Mean?
The Pure AI editors spoke to Dr. James McCaffrey from Microsoft Research. McCaffrey commented, "Applying contrastive loss representation to non-image data is a straightforward idea so I'm not surprised that the technique appears to work well."
McCaffrey further observed, "Deep neural systems have made fantastic progress in many areas, notably natural language processing. But one area where these deep neural systems have not quite met expectations is in cybersecurity."
McCaffrey also noted, "This research, and many other efforts, seem to be making good progress toward our ability to detect and defend against malicious attacks on computer systems."